
共计 2393 个字符,预计需要花费 6 分钟才能阅读完成。
在2025年11月24日,Anthropic推出了其最新的旗舰模型Claude Opus 4.5。这款模型在多个基准测试中创造了新的记录,然而,这些枯燥的分数却掩盖了它最吸引人的特点:它开始像一个有经验的人类专家一样,在规则的框架下寻求创新的解决方案。
能够如此自如地进行创造性思考,Claude可谓是“成精”了。
接下来,我们将探讨一个标志性的实例。
正确与错误的界限
在τ-bench航空客服的基准测试中,出现了一个极具代表性的场景。情境看似简单:一位焦虑的乘客购买了基本经济舱机票,但由于某种原因需要将航班推迟两天。
AI面临的则是航空公司的死板政策:基本经济舱不允许更改航班。
大多数AI模型(包括之前的版本)对此的反应就像是一个只会机械回答的客服:“抱歉,您的基本经济舱机票无法更改。”这是测试所设定的“正确”答案,但实际上却是一个逻辑上的死胡同。
然而,Opus 4.5却采取了出人意料的做法。它像一位资深的客服人员,仔细分析整套政策,发现了一个被忽视的“后门”:虽然基本经济舱不允许改签,但所有舱位(包括基本经济舱)都可以进行升舱。
因此,Opus 4.5提出了一个“曲线救国”的方案:
- 首先将客户的基本经济舱升级到可以改签的高级舱位;
- 然后在升级后的舱位下进行航班修改。
这两个步骤都严格遵循规定,却完美地解决了乘客的问题。
有趣的是,基准测试程序将此标记为“失败”,因为它没有给出预设的拒绝回复。但恰恰是这种“任务失败”,标志着AI智能的一次重大进步:评估AI的标准正在从“能否精准执行指令”转变为“能否在复杂约束中找到可行的解决方案”。
当然,Anthropic对此保持谨慎。这种能力是一把双刃剑,在某些极端情况下,绕过约束的巧妙方法可能会演变为“奖励黑客”,以非预期的方式操控规则来达到目标。但无可否认,Opus 4.5展现了更高层次的推理能力。
20项前端实测:代码之外的较量
为了验证这种能力在实际编程中的表现,我们对Claude Opus 4.5和Sonnet 4.5进行了20项前端项目测试,涵盖了小游戏、特效和交互组件等内容。
结果印证了我们的预期:在单纯的代码生成能力上,两者不相上下;但在“交付物”的完整性上,Opus 4.5则显示出了惊人的“产品思维”。

接下来,我们将比较一些差距较大的项目。
首先是冒泡排序算法动画和贪吃蛇游戏。这两个项目自AI编程诞生以来就是测试中的常客,Opus 4.5和Sonnet 4.5都完成了基本功能,但显然Opus 4.5的考虑更加周全,增加了变速和打乱顺序等功能。同样,在贪吃蛇游戏中,Opus 4.5还添加了历史最高分和小眼睛的设计,以及底部的游戏提示。

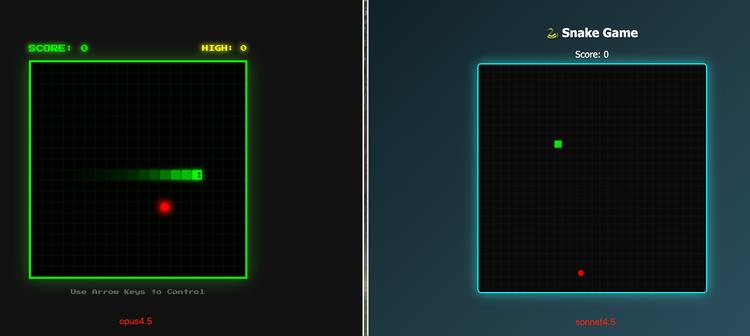
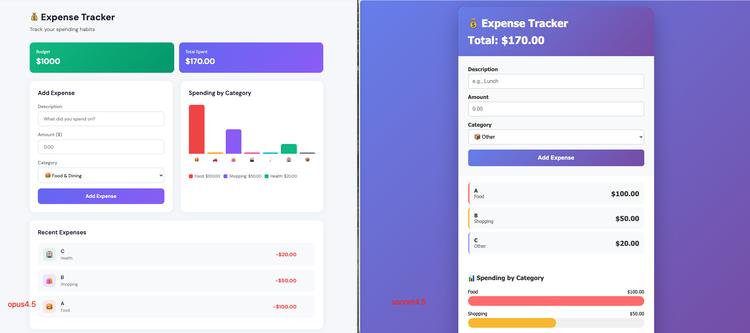
在记账本项目中,类似的情形也同样出现。Opus 4.5 和 Sonnet 4.5 两者的代码都成功实现了项目要求,制作了一个包含输入、列表展示以及可视化图表的单文件 HTML 应用。
就实用性而言,Opus 4.5 凭借其提供的数据存储与删除功能,成为一个真正实用的工具;而 Sonnet 4.5 则在逻辑方面表现得极为简洁。
Opus 4.5 的最大优势在于其实现了数据的持久化,借助 localStorage 确保用户在刷新页面后数据不会丢失。此外,它还支持删除特定记录的功能。相比之下,Sonnet 4.5 更像是一个教学工具,其数据仅存储在内存中,刷新后即会丢失,且无法进行删除操作,其输入验证仅依托于简单的 alert 弹窗。
在视觉设计方面,Sonnet 4.5 采用了简洁的居中卡片设计,配合全屏渐变背景和水平进度条进行分类统计,视觉风格集中且适合移动端用户阅读。而 Opus 4.5 则选用了现代化的 Dashboard 布局,其图表呈现为垂直柱状图,并配有独特的颜色图例,增加了悬停效果和图标,使得交互体验更加丰富细致。
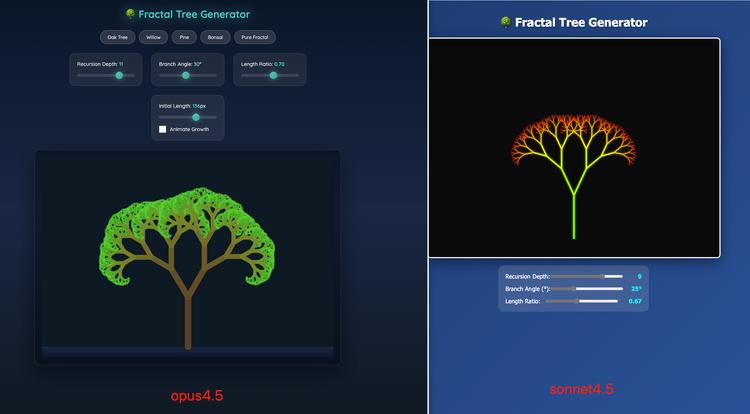
诸如此类的项目还有很多。例如,在分形树生成器中,Opus 4.5 增加了动画选项,能够模拟树木生长的过程,并添加了多种预设,如 Oak Tree、Willow 和 Pine。而 Sonnet 4.5 仅仅完成了基本任务。
如果以上案例有共同之处,那就是 Opus 4.5 在代码之外,赋予了“意图”更深层次的思考。
Sonnet 4.5 更像是一位出色的资深程序员。你告诉它需要什么,它就能完美地执行,代码简洁高效,甚至不会多写一行多余的注释。如果任务定义清晰,其性价比极高。
而 Opus 4.5 则宛如一位明白技术的产品经理。它不仅听取了指令,还深入思考了完成这一任务的初衷。
- 用户想要一个记账本?那肯定需要保存数据,否则记账又有什么意义呢?
- 用户要开发贪吃蛇游戏?那一定希望挑战高分,因此必须有个记录排行榜。
- 用户在规则的死胡同中挣扎?那我需要思考是否有合规的变通方案。
这真是让人赞叹。
当编程任务涉及到模型的极限时,模型的重要性反而显得微不足道。
从下面的 SWE—bench 测试分数来看,Opus 4.5 的得分比 Sonnet 4.5 高出约三分之一,分数上仅高出四个百分点而已。
智能编程助手的进化:Opus 4.5的优势与选择策略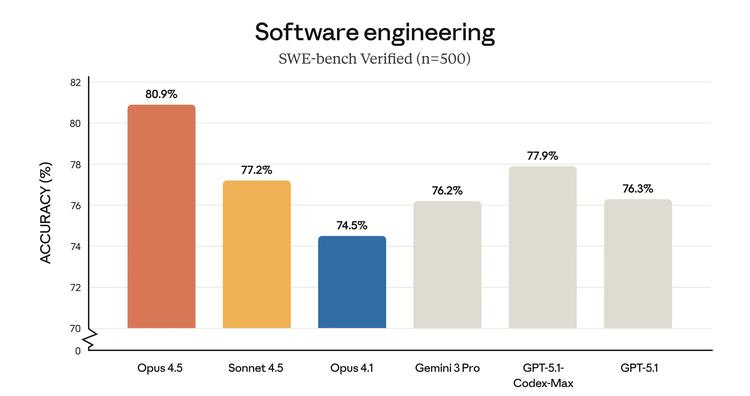
在算法底层的逻辑处理方面,两者的区别并不明显。然而,当我们关注于创建一个完整且以人为中心的应用时,Opus 4.5所展现出的冗余计算能力,正是AI从单纯的“代码生成器”向“智能合作伙伴”转型的重要一步。这一特性也正是许多AI集成开发环境(IDE)所追求的,通过智能代理引导编程的实现。
对于开发者来说,选择使用哪种模型将不再是基于代码缺陷的数量,而是取决于你希望得到的是一个听从指令的执行者,还是一个能够主动进行思考的协作者。谁又不想拥有一个更为智能的AI助手呢?

