共计 2130 个字符,预计需要花费 6 分钟才能阅读完成。
2025年的AI编程领域再度引发热议。根据北京时间9月30日的消息,Anthropic正式推出了Claude Sonnet 4.5,该模型被官方誉为“全球顶尖的编程模型”。此次更新在智能体构建、计算机应用、推理和数学能力等方面取得了显著进展,Claude在编程领域的领导地位得以巩固。
许多业内专家认为,Anthropic选择在此时发布更新具有重要意义——仅一周后,OpenAI将召开年度开发者大会;而不久前,OpenAI推出了增强智能体编程能力的GPT-5-Codex,声称能够独立完成长达7小时的复杂任务。
此次更新中,Anthropic将标准进一步提升:Sonnet 4.5在处理复杂和多步骤任务时,能够保持超过30小时的持续专注力。
这一能力得到了行业的认可,iGent AI的首席执行官表示,Sonnet 4.5“重新定义了行业标准”,它能够独立处理超过30小时的代码,使工程师在极短的时间内完成几个月的复杂架构工作,同时保持代码库的一致性。
从官方评测结果来看,Sonnet 4.5在编程和数学等多项测试中超越了GPT-5和谷歌的Gemini2.5 pro。
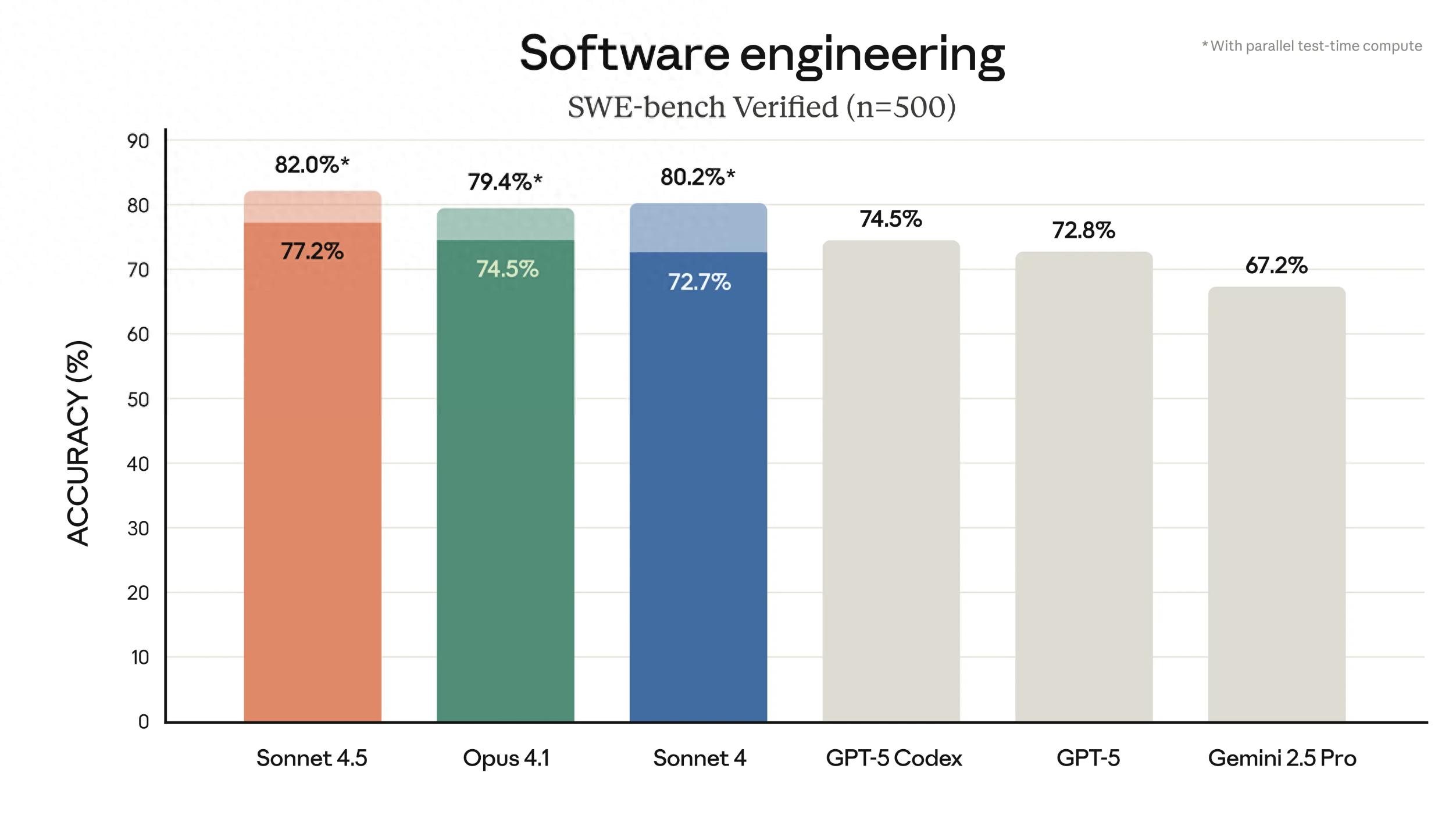
在真实编程水平的SWE-bench Verified测试中,Claude Sonnet 4.5荣登第一,超出GPT-5-Codex达7.5个百分点。
在针对计算机环境的开放任务基准测试OSWorld上,Sonnet 4.5以61.4%的得票率领先,而四个月前,Sonnet 4的得票率为42.2%。

此外,针对特定专业领域,Anthropic指出,Sonnet 4.5在金融、法律、医学和STEM领域的专家评估中,表现出比包括Opus 4.1在内的旧模型更强的领域知识和推理能力。
伴随此次模型的升级,官方还对产品体验进行了改进,包括引入“检查点”功能,允许用户随时保存进度并一键回退。同时,终端界面得到了重新设计,代码执行和文件创建现在可以直接在对话中完成。在官方演示中,Claude能够直接在浏览器内操作,导航网站、填写电子表格及完成各项任务。
一位AI行业博主指出,“如果之前的Claude是为程序员设计的,那么现在的Claude则是为白领服务的,可以直接编辑办公软件,处理邮件。”尽管目前尚未达到生产级别,但代码Agent在软件工程中的应用很快将扩展至所有知识工作领域,这仅仅是个开始。
此次更新中,一个备受瞩目的临时预览功能是“Imagine with Claude”。在此功能中,Claude实时生成软件,不依赖预设功能或提前编写的代码,用户所见的一切都是Claude根据实时互动需求当场创建的。这或许展示了大模型语言操作系统的未来,尽管目前尚不成熟,该功能将在接下来的五天内仅对Max订阅用户开放。
随着模型的升级,许多AI编程领域的创业者也纷纷为Claude“背书”。Cursor的首席执行官Michael Truell表示,Sonnet 4.5展现了卓越的编码性能,并在长期任务方面取得了显著进步。这进一步证实了许多使用Cursor的开发者选择Claude来解决最复杂问题的理由。Cognition的联合创始人兼首席执行官Scott Wu也表示,Sonnet 4.5显著提升了Devin的规划能力和端到端评估成绩。
在定价方面,Sonnet 4.5保持与Sonnet 4一致,为每百万输入tokens收取3美元,每百万输出tokens收取15美元。然而,与Anthropic前代旗舰模型Opus 4.1(输入15美元,输出75美元)相比,成本降低了五倍,开发者现在能够以更低的成本获取在多任务上表现超越旗舰的模型。
自2023年3月推出以来,Anthropic在编程和数学等领域持续保持领先,并吸引了大量客户。在Cursor平台上,Claude仍旧是最受欢迎的调用模型。
月初,Anthropic宣布完成了130亿美元的融资,最新估值达到1830亿美元,成为全球估值第四的独角兽。当时官方透露,预计到2025年8月,其年化收入将超过50亿美元(约357亿元人民币),而2025年初的收入约为10亿美元,八个月内,其商业化能力快速增长。
今年2月,Anthropic推出了自家的AI编程工具Claude Code,并在今年5月宣布全面开放,从研究预览转为正式产品。Anthropic提到,Claude Code在三个月内使用量增长超过10倍,产生超过5亿美元(约36亿元人民币)的运营收入。
然而,Anthropic目前也面临一定挑战。在过去两个月内,用户普遍反映Claude模型的质量出现“断崖式下滑”,质疑其为了控制成本而降低了模型性能,甚至引发开发者的大规模退订。Anthropic对此回应称是由于独立Bug引起,绝非“故意降智”,但这一信任危机至今尚未完全平息。
(本文来自第一财经)