共计 3872 个字符,预计需要花费 10 分钟才能阅读完成。
在这个周末,人工智能领域发生了令人瞩目的事件。OpenAI成为了舆论的焦点,Google、Meta以及多位AI领域的知名人士纷纷参与其中,引发了一场热烈的讨论。
用一句话来总结就是:OpenAI的研究人员宣称GPT-5发现了10个悬赏数学问题的解决方案,舆论误以为GPT-5独立提出了解决方法,后来发现其实仅仅是检索了已有文献,这引起了学术界的广泛嘲讽以及对AI夸大宣传的激烈探讨。
这一切的起源可以追溯到几条引发热议的推文。
GPT-5真的解决了悬赏难题吗?
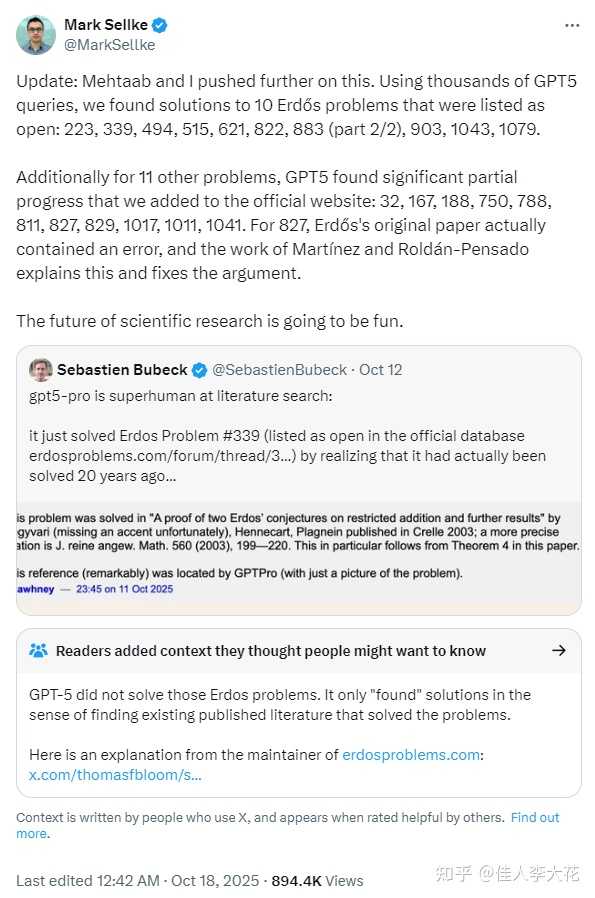
10月12日,Sebastien Bubeck在推特上发文称,GPT-5在文献搜索方面表现出色,发现了Erdős问题339已经得到解决,但其状态在官方数据库中仍未更新。
10月17日,OpenAI的研究人员Mark Sellke转发了这一消息,并表示他与Mehtaab利用GPT-5模型进行了深入研究,通过数千次查询,考察了http://erdosproblems.com网站上标记为“开放”的Erdős问题。
他们声称“发现了”10个问题的解决方案(问题编号:223、339、494、515、621、822、883(第2/2部分)、903、1043、1079)。此外,他们在另外11个问题上也取得了部分进展。
OpenAI的首席产品官Kevin Weil对此进行了转发。
这些问题源自数学家Paul Erdős提出的未解决问题列表,其维护者为数学家Thomas Bloom。
OpenAI的副总裁Sebastien Bubeck再次转发,并宣称“AI加速科学的时代已经来临”,同时宣布Mark Sellke加入OpenAI。
随之而来的是,公众和媒体普遍认为GPT-5在数学推理方面实现了突破,能够独立解决长期困扰数学家的难题。
剧情逆转:“这太尴尬了”
然而,这场庆祝活动仅仅持续了几个小时,就发生了反转。
谷歌DeepMind的首席执行官Demis Hassabis在Sebastien Bubeck的推文下评论称:这太尴尬了。
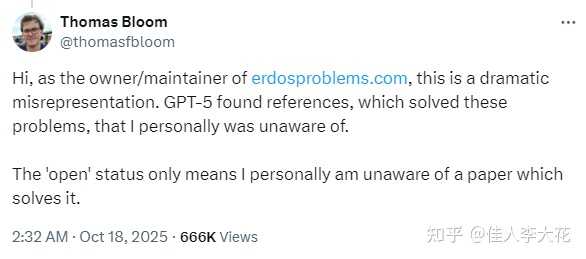
Hassabis接着引导公众关注该数学难题网站的维护者、数学家Thomas Bloom的澄清。
Thomas Bloom指出,OpenAI的表述存在“戏剧性的误解”。网站上将这些问题标记为“未解决”,仅仅是因为他个人不知道相关解答已经发布,并不代表数学界没有人解决这些问题。
换句话说,GPT-5更像是一个高效的学术搜索引擎,而不是一位数学专家。
Sebastien Bubeck随后删除了相关推文并表示歉意,称“我并无意误导任何人,我认为我的表述很清楚,抱歉”。他强调,AI在文献搜索方面的价值是显而易见的,因为“我非常清楚搜索文献有多困难”,这能加速科学研究的进程。
Kevin Weil也删除了推文并承认“我实际上误解了我们的结果(这真是尴尬)”。Mark Sellke也对这一更新进行了转发。
自食其果的GPT宣传
对此,Lecun也发表了尖锐的评论,称OpenAI被自己对GPT的宣传所困扰(Hoisted by their own GPTards),讽刺其自我设限。
注:这个短语源自莎士比亚的戏剧《哈姆雷特》,原意为“被自己的炸药炸伤”,这里的petard(炸药)改为GPTards。
%5C%22https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650996473&idx=1&sn=a3949c755279c774d065eac6f18d8bb0&chksm=85ae9a0ecdb40f5c643d649638f2815c671a43f2a334f76cf8035863eb9c1380204ba4e595fe&scene=0&xtrack=1#rd%5C%22
OpenAI「解决」10道数学难题?哈萨比斯直呼「尴尬」,LeCun辛辣点评
GPT-5的这一事件实际上展现了一种典型的“路径”:
研究者兴奋分享 → 机构或高管放大 → 竞争对手与学界校正 → 舆论反转。
社交媒体上的简短表述往往容易引发误解。
例如,“found solutions”这个词组,有的人可能理解为“找到了现成的答案”,而另一些人则可能将其解读为“创造了全新的方法”。
这种模糊性常常导致误解。
这与传播学中的“萨根标准”不谋而合,即“非凡的主张需要非凡的证据来支撑”(Extraordinary claims require extraordinary evidence)。
你所声称的越是惊人,就越需要用足够有力的证据来支持。
当然,我认为上述在X上发布的消息并不存在“歧义”,它的意思非常明确,即“解决了”!
正因其用词如此“大胆”和“嚣张”,所以在反转时显得格外……有趣?

Yann LeCun对此进行了尖锐的批评:
“Hoisted by their own petard”是一个经典的英语习语,最初出自莎士比亚的《哈姆雷特》,其原意为“被自己的炸药炸伤”。
LeCun所改编的“GPTards”一词显然带有贬义,嘲讽意味明显。
Emily Bender等人在《Stochastic Parrots》中指出,大型语言模型虽然擅长生成流利的语言,但语言的流畅性并不等于新知识的创造。

在任何科研领域,尤其是数学领域,当我们提到一个问题被解决时,通常意味着有人提出了新的正确证明或创造了严格的新方法,并且这一成果已通过同行评审。
有时问题的答案早已存在于某篇论文中,只是人们尚未找到,这种情况被称为信息发现。
显然,这两者的价值是截然不同的。
陶哲轩针对AI在数学领域的应用表达了自己的观点:
https://mathstodon.xyz/@tao/115385022005130505

陶哲轩指出,他逐渐意识到,AI在数学领域最有价值的地方,并非是利用最强大的AI模型去攻克最艰难的数学难题。尽管在这一领域确实会出现一些成功的个别案例,尤其是在投入大量计算资源和专家精力的情况下。
更为实用的做法是:
AI在数学研究中的角色与挑战:不应迷失方向
陶哲轩逐渐发现,利用中等水平的AI工具来加速和扩展那些普遍且耗时的研究任务,虽然这些任务看似平常,却是科研活动中不可或缺的一部分。在进行这些任务时,AI的使用应依赖于人类专家在这一领域累积的知识与经验。这些经验不仅可以引导AI的操作,还能有效验证AI的输出结果,并将其安全地融入研究流程中。
陶哲轩特别提醒我们:
在这种应用场景下,AI所“生成”的结果,实际上人类专家也能够完成,只是需要投入更多的时间与精力。然而,这一点恰恰是其优点,因为这表明AI所产生的结果是人类专家能够轻松且可靠地评估和确认的,而且这些结果可以迅速转化为专家们熟悉的工作格式。
换句话说,AI当前最合适的角色不是独立解决顶尖难题,而是作为高效助手,支持研究者完成那些他们已知如何处理但耗时的工作。
这种方式的好处在于,研究者能够全面理解并核实AI的工作成果,避免出现AI给出答案但研究者却无法理解或确认其正确性的情况。
目前,许多以GPT为代表的AI模型都是封闭源代码的,这意味着其内部工作机制和训练数据并不对外公开。
因此,外界很难独立验证这些模型的真实表现……
当模型产生一个结果时,我们难以判断它是从现有文献中提取并整理的信息,还是仅仅是对已有知识的语言重组,或者是进行了一定程度的原创推理和创新。
美国国家标准与技术研究院(NIST)提出的AI风险管理框架强调,值得信赖的AI系统应具备三个核心特征——结果可验证、决策过程可解释、运作方式透明。
缺乏这些特征,人们可能会将AI作为实用工具所展现的“能力”误解为科学研究中的重大“突破”。

近年来的多项研究揭示了一个共同问题:
大型模型在训练过程中可能已经“接触”过评测基准的测试数据,这一现象被称为数据污染。
这些模型是通过海量的网络数据进行训练的,而许多评测基准同样是从互联网资料构建的,因此训练数据与测试数据之间可能存在重叠。
当模型在训练阶段见过测试集中的题目时,其在评测中的高分可能并非源于真实的推理能力,而仅仅是对答案的记忆。
有研究提出了一种测试方法,通过遮挡多项选择题中的某个错误选项,来让模型猜测被遮挡的内容。

结果显示,ChatGPT和GPT-4在被“广泛使用”的MMLU评测基准中,成功猜测被遮挡选项的比例分别为52%和57%。
考虑到错误选项的种类本应非常多样,毕竟正确答案只有一个,而错误答案可以千变万化。
模型能够如此准确地预测测试集中的具体选项,强烈暗示它们在训练过程中接触过相关数据。
这种数据污染所引发的问题,实际上就是GPT-5这次事件的源头,可能导致公众和研究者产生误解。
当人们看到模型在数学或逻辑推理题上获得高分时,往往会认为模型真正掌握了推理能力,确实“学会了解题”。
然而,实际上模型只是记住了测试集中的题目和答案,这些高分并不能证明模型具备真正的推理能力。
再加上“夸张的宣传文案”,因此出现这种“大模型无所不能”的误解也就不足为奇了。
我认为,正如陶哲轩所说的那样,让大型模型回归其应有的角色,完成其擅长的检索、归纳和总结工作,或许才是当前大型模型的合理使用之道。