共计 3076 个字符,预计需要花费 8 分钟才能阅读完成。
Kimi K2 Thinking 模型正式开源,令人瞩目
Kimi K2 Thinking 模型正式开源,令人瞩目
最近,国内的开源大模型再次让我感到惊艳!不久前,MiniMax M2的开源使得我国的大模型在开源排行榜中名列前茅。而在美国,Kimi团队几日前也发布了第二代的Kimi K2 Thinking模型,并且已经开放源代码。
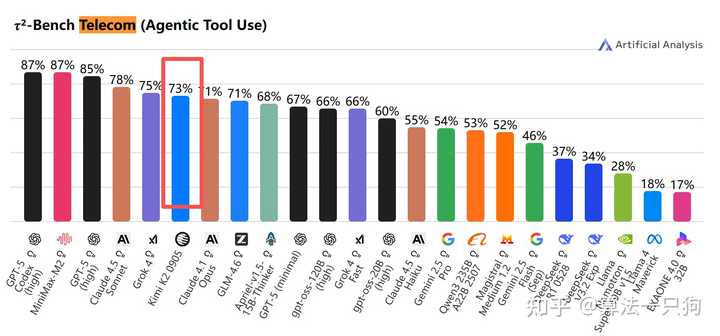
根据Artificial Analysis网站的数据,在²-Bench Telecom智能体工具基准测试中,Kimi K2模型的得分为73%,仅次于GPT-5和Claude等顶尖模型。
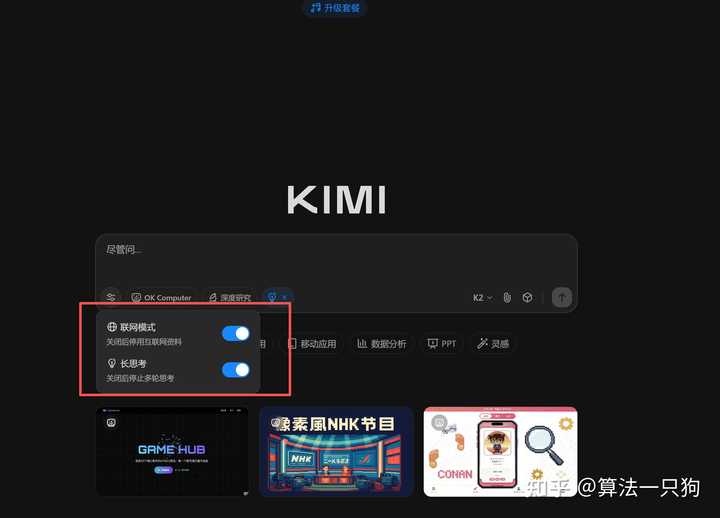
如果想快速体验,可以访问Kimi的官方网站,开启思考模式,即可体验Kimi K2 Thinking模型。
从整体架构来看,Kimi K2与R1模型有相似之处:
- 两者的输入流程大致相同:tokenized text → token embedding → 堆叠的 Transformer 块 → 最终的 RMSNorm → 线性输出层。
- 二者均采用了 RoPE(旋转位置编码)。
- 都标示了:支持上下文长度为128k(Supported context length of 128k tokens)。
- Embedding 维度均为7168,表明词向量的规模是一致的。
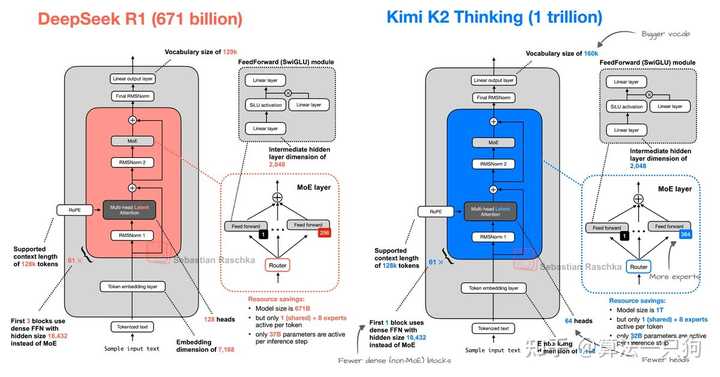
但在具体细节上,二者存在一些差异:
- Kimi模型的总参数量更为庞大,但单层的注意力机制并没有过于“宽松”,可能是为了将更多资源分配给MoE专家数量。
- Kimi的整体模型规模更大(1T对比671B),但在单次推理时激活的参数却更少(32B对比37B)。这正是MoE的优势:虽然模型参数池可以扩展,但每次使用的并不一定多。
- Kimi K2的总模型大小为1T,但每次推理仅使用32B,并且专家数量更多、词汇量更大、稠密块更少。
模型性能
1.全面能力跻身顶尖行列
当前,许多国内最新的大模型更加专注于Agent的能力。Kimi K2 Thinking模型如同我之前提到的MiniMax M2一样,融入了“模型即Agent”的理念。它能够原生调用多种不同工具,来完成各类任务。
在多项基准测试中,如人类最终考试(Humanity’s Last Exam)、自主网络浏览能力(BrowseComp)以及复杂信息收集推理(SEAL-0)等,Kimi K2均展现了SOTA水平,并在Agentic搜索、编程、写作及综合推理等方面取得了显著进展。
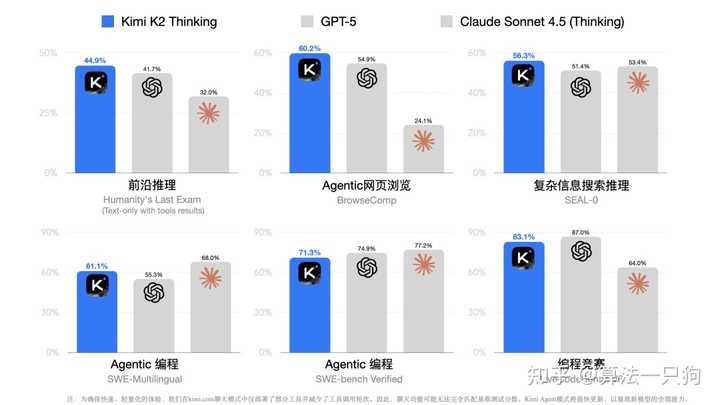
Kimi K2 Thinking模型具备无需人工干预的自主能力,能够稳定进行多达300轮的工具调用与持续多轮思考,进而有效应对复杂的用户需求。该模型通过同步扩展思考Token数量与工具调用次数,显著提高了智能体的推理和任务执行能力。
在“人类最终考试”中,Kimi K2 Thinking的表现超过了GPT、Claude等模型,取得了优异的成绩。这项考试是一个全面的学术评估,涵盖100多个专业领域,并要求在封闭环境中使用搜索、Python和网络浏览等工具。模型以44.9%的分数创造了先进纪录,展示了其卓越的推理和解决问题的能力。
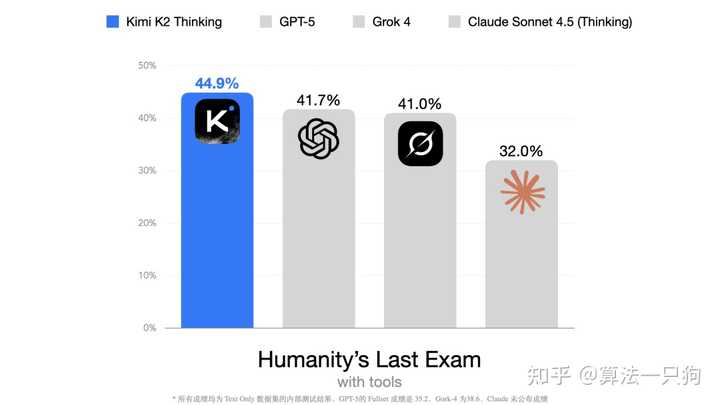
例如,Kimi K2 Thinking通过5轮搜索和推理,结合每轮获得的新信息,逐步深入,最终得出了答案:

2.自主搜索与浏览能力显著提升
复杂的搜索场景是评测大模型能力的重要指标之一。在OpenAI的BrowseComp基准测试中,该测试主要考察AI代理在信息过载环境下进行网络浏览时的持久性与创造性(类似于人类研究员的“刨根问底”行为),Kimi K2 Thinking的表现令人惊叹。它以60.2%的得分大幅超越了人类平均水平的29.2%,成为新的顶尖模型,突出其在复杂搜索任务中的深度探索能力。
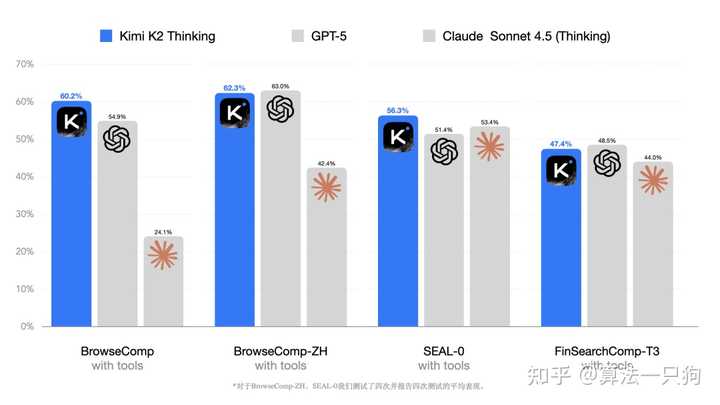
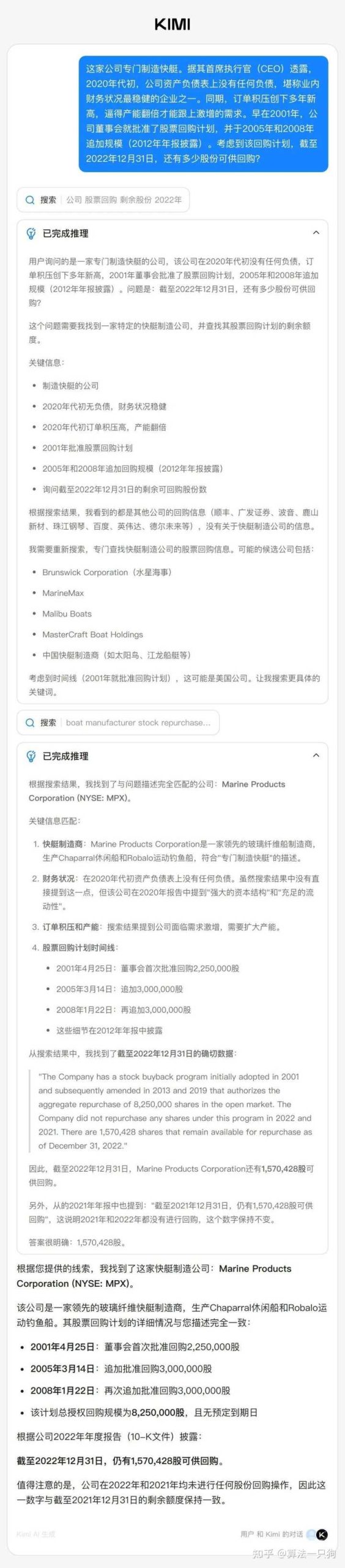
例如,在以下案例中,Kimi K2 Thinking经过两轮搜索与思考,首先根据已知的股票回购信息找到了这家制造快速的公司,随后又在美国证券交易委员会(SEC)官网上找到了相关的股票回购公告,得出了准确的答案:
3.编程能力不断增强
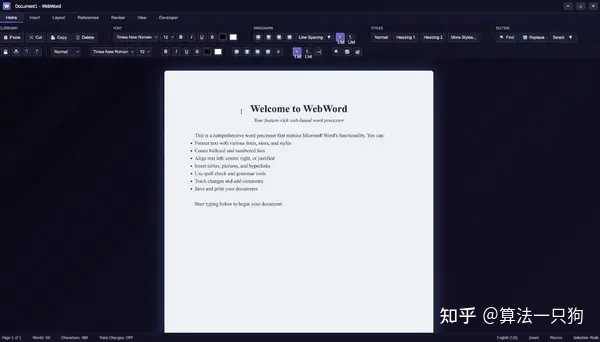
编程能力也是衡量大模型实力的重要场景之一。Kimi K2 Thinking在编码能力上有了显著进步,在多项软件工程基准测试中,包括多语言、验证集和终端操作,表现优异。该模型在前端任务中,如HTML和React开发,能够迅速将创意转化为响应式产品。在自主编码场景下,它能够智能调用工具,结合软件代理,处理复杂的多步骤开发流程,例如现在可以协助实现功能完备的文字编辑器。
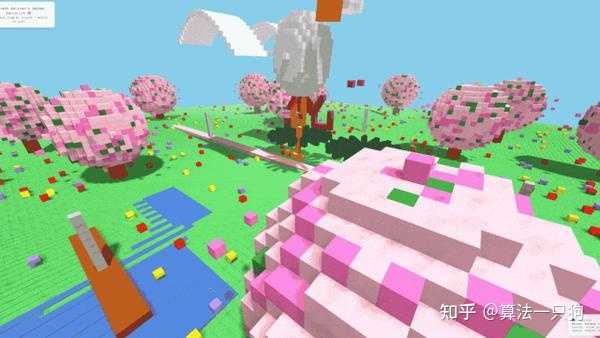
Kimi K2 Thinking同样能够帮助用户创作出华丽风格的体素艺术作品:
初步体验测评
1.常规测试
Q1:总结内容,生成知识卡片网页
请总结这个网页(https://www.qbitai.com/2025/11/349957.html),生成一个美观、精致的知识卡片网页内容。
在整体视觉风格方面,紫白色调与科技渐变相结合,现代感十足;图标均统一为圆角矢量形,展现了一定的柔和感。同时,层次也较为清晰,使用标题蓝点与浅色卡片区分模块。


与GPT-5的效果进行比较,两者各有千秋。GPT-5的效果更加模块化,并且

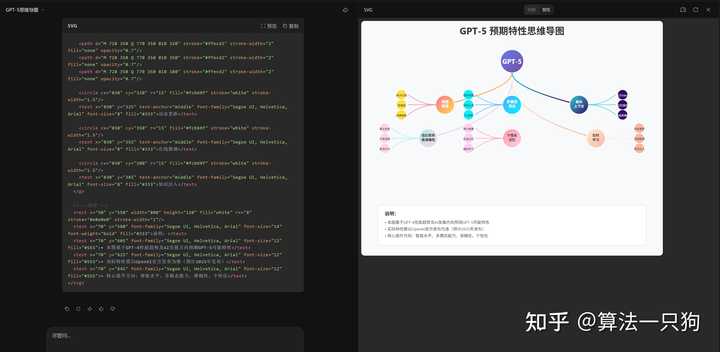
Q2:使用SVG绘制思维导图,介绍GPT-5的特点
Kimi K2列出了GPT-5的一些特点,然而从生成的SVG来看,线条略显杂乱,未达到理想的美观效果。
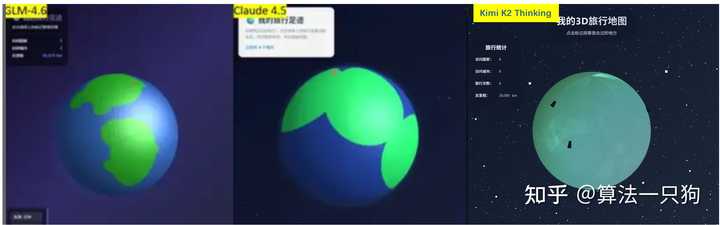
Q3:绘制3D地球
探索未来:Kimi K2 Thinking的崭新旅程
借助Three.js和JavaScript,我构建了一个网页,展现了一个基于数组的三维世界,记录了我曾游历的地点。通过点击3D地球上的标记,用户将体验到缩放动画,同时能打开包含照片的详细旅行信息。与其他不同的模型相比,Kimi生成的3D地球具备自动旋转的功能,但缺少具体地图的信息。
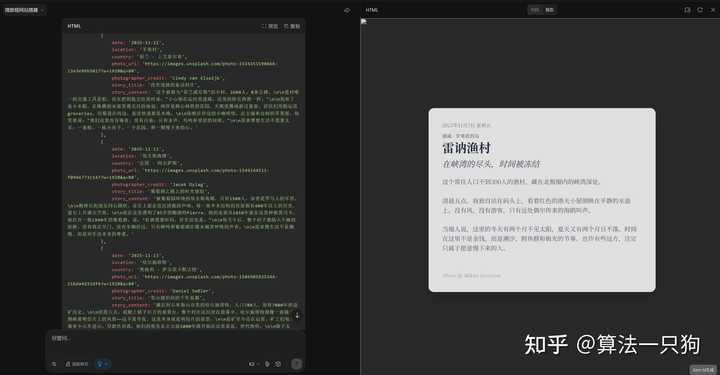
Q4:创建一个“微旅程”网站,每日推荐一张世界上鲜为人知的角落的照片以及一则故事。
这个网站的构建过程非常顺利,同时也展示了一些关于这些地方的精彩故事。
2. 游戏代码编写与测试
Q1:利用Three.js开发一款3D战斗机对战游戏,玩家可以在城市上空飞行,并通过触屏或键盘进行操作。
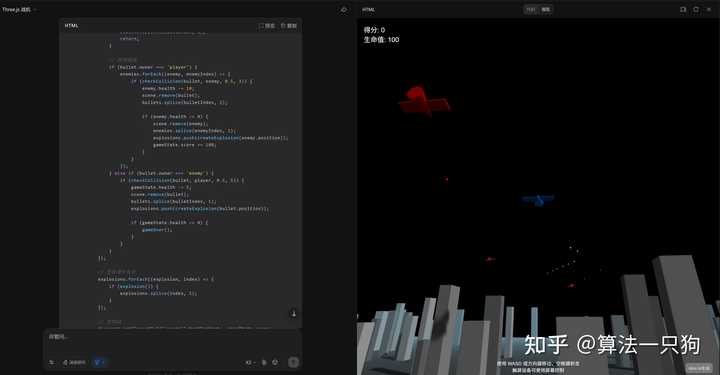
尽管城市的建筑物并未具体呈现,但游戏的基本玩法已然完成。
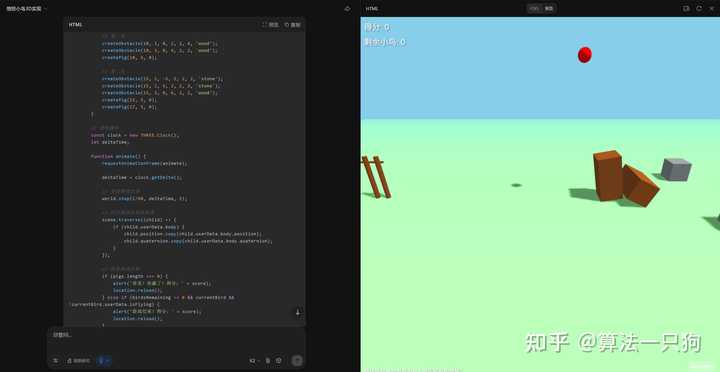
Q2:使用Three.js创建一款愤怒的小鸟3D游戏
游戏界面已初步成型,并且支持简单的操作,但在视觉设计上仍显得有些简单。
总结思考
总体而言,Kimi K2 Thinking标志着国内大型模型在“思维能力”及“工具链互联”领域取得了显著的进展。它不仅仅是一个语言模型,更是一个具备多轮自主推理、信息收集、代码执行和网页浏览等多种复合能力的智能体。这一进展表明,我们正在逐步迈向“模型自主完成任务”的新阶段。
(1)在技术方面,1TB的参数量与INT4精简激活架构,使得推理速度和成本达到了更加平衡的状态。同时,256K超长上下文与增强版工具调用系统为复杂任务和长程推理奠定了基础。
(2)从体验的角度来看,在实际测试中,Kimi K2 Thinking能够有效结合搜索、代码生成和视觉创作,整体体验流畅,生成的内容逻辑性强且自然,尤其在多轮思维链任务中表现卓越。
可以预见,伴随着越来越多的国内企业参与到“Thinking模型”的竞争中,我们即将迎来一个从“指令执行”向“自主思考”转变的新时代。
未来或许不再是“我们在使用模型”,而是“模型在辅助我们思考”。