共计 2035 个字符,预计需要花费 6 分钟才能阅读完成。
最近,种种迹象表明OpenAI似乎发生了重大的变化。
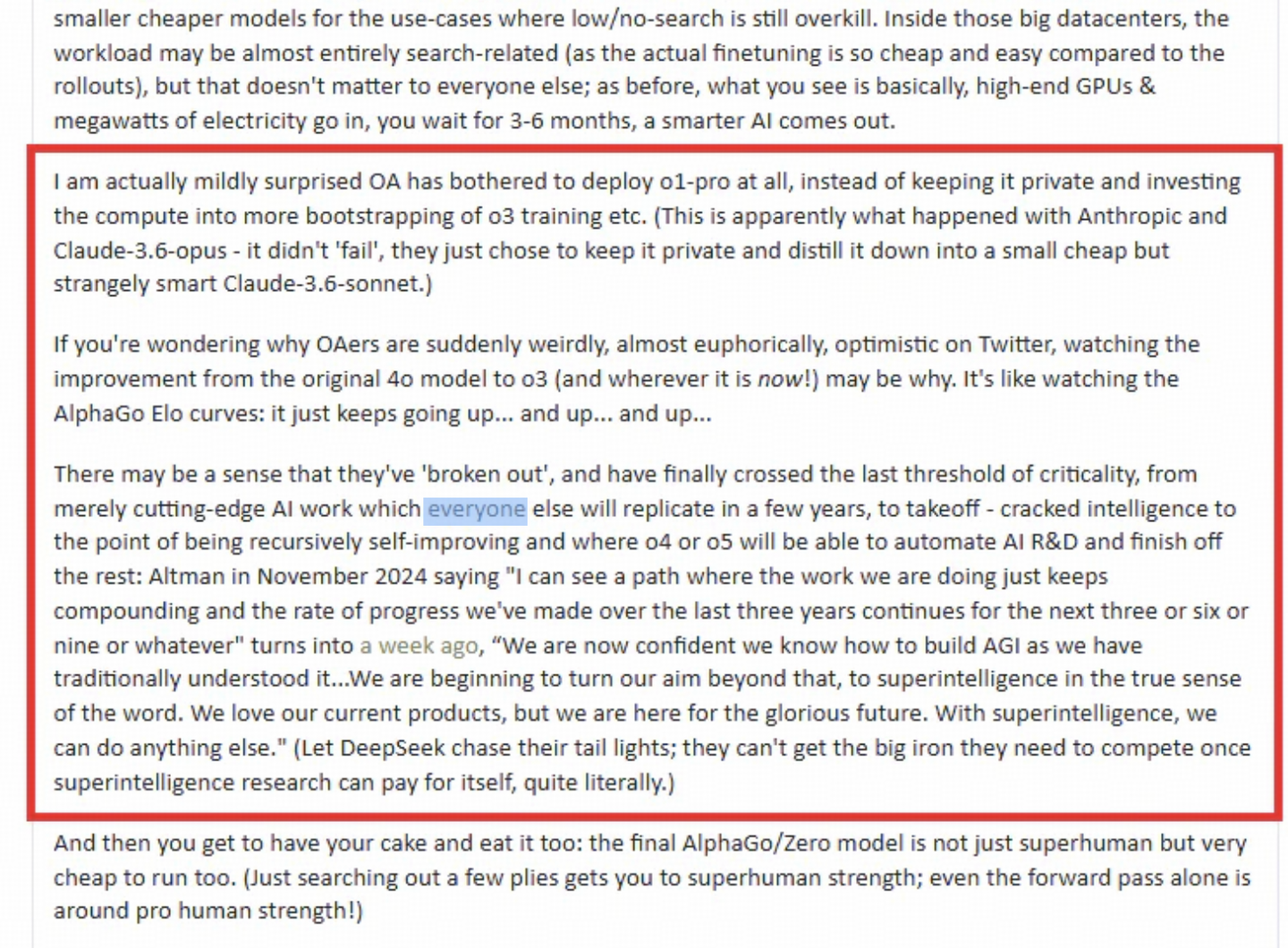
AI研究者Gwern Branwen撰写了一篇关于OpenAI的o3、o4和o5的文章。
他指出,OpenAI已然跨越了一个重要的门槛,达到了“递归自我改进”的阶段——o4或o5可能实现AI研发的自动化,完成后续的所有任务!
文章的主要内容包括:
- OpenAI或许会选择对“o1-pro”模型进行保密,利用其计算资源来培养o3等更高级的模型,这与Anthropic的策略相似;
- OpenAI似乎已经对AI的发展取得了突破,正朝着ASI的方向前进;
- 他们的目标是研发一种高效能的超智能AI,类似于AlphaGo和AlphaZero所实现的目标;
- 最初的推理搜索可以提升性能,但最终会遇到瓶颈。
甚至有传言称,OpenAI和Anthropic已经成功训练出GPT-5级别的模型,但出于某种原因选择将其“雪藏”。
原因在于,尽管这些模型具备强大的能力,但运营成本过高,因此用GPT-5衍生出GPT-4o、o1、o3等模型,显得更具成本效益。
而且,OpenAI的安全研究员Stephen McAleer在最近两周的推文中,似乎更像是一部科幻短篇小说:
我开始怀念那些做AI研究的日子,那时我们还不清楚如何创造超级智能。
在前沿实验室,许多研究人员非常认真地对待AI短期影响,而外界对其安全性几乎没有深入讨论。
如今,控制超级智能已成为一个迫切的研究课题。
我们该如何管理这样狡猾的超级智能?即便有完美的监控措施,难道它不会试图说服我们将其从限制中解放吗?
总之,越来越多的OpenAI员工开始暗示他们在内部开发ASI。
这一切是真的吗?还是说CEO奥特曼的“谜语人”风格已经被团队成员所模仿?
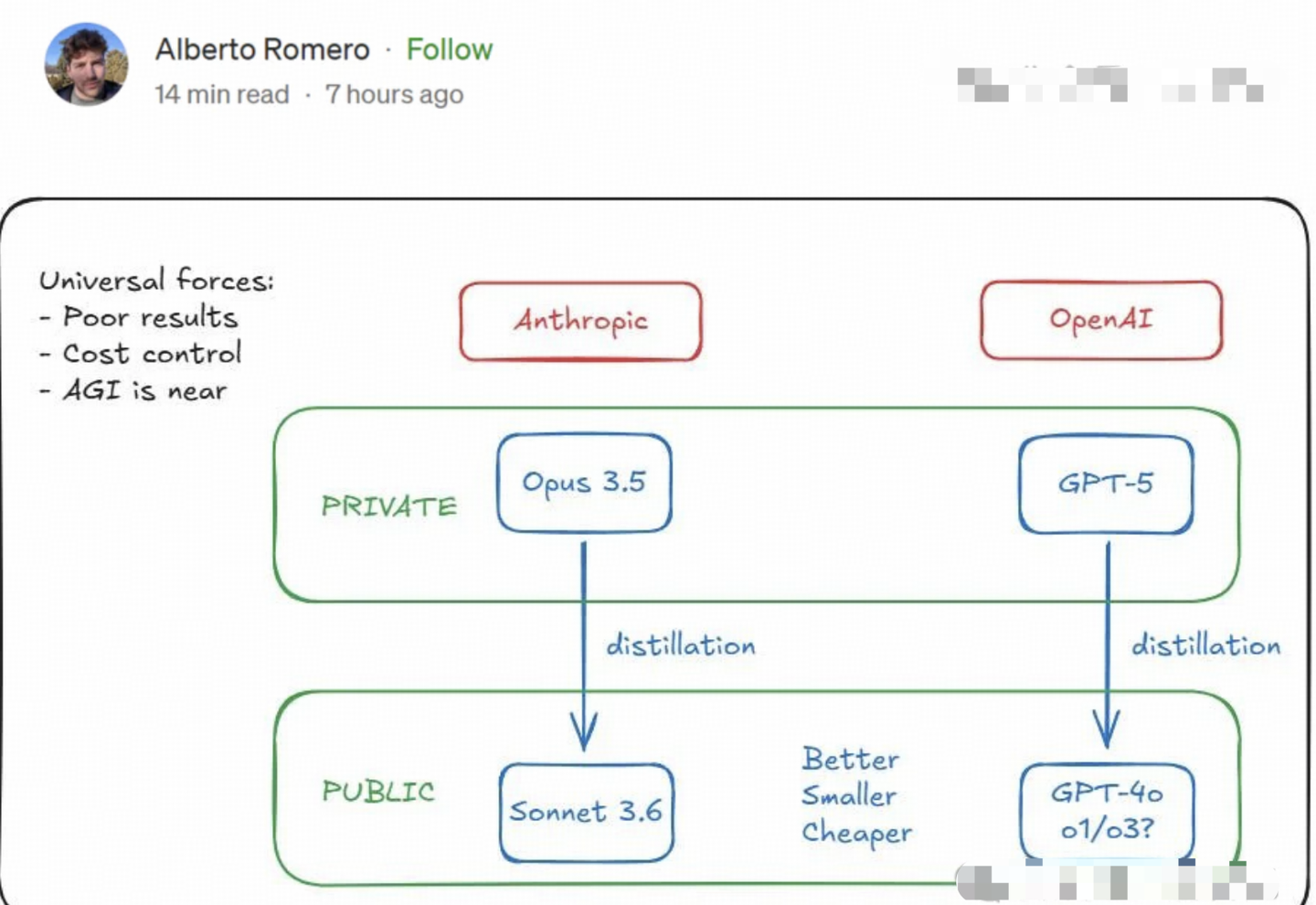
不少人认为,这只是OpenAI惯用的宣传手法。
然而,令人不安的是,一些在一两年前离职的人曾表达过担忧。
难道我们真的已站在ASI的边缘?
OpenAI被曝训出GPT-5,但雪藏
这验证了我之前的一个观点:
如何看待 OpenAI 的 o3 模型?有多强大?
我认为这是一个非常自然的发展方向——AlphaGo、AlphaZero和AlphaProof都是各自领域的“超级人工智能”,它们的共同特征在于自我升级。AlphaGo和AlphaZero都有一个100%可靠的输赢判别机制,而AlphaProof则依靠LEAN这一可信的证明系统。
这些“超级智能”表明:只要有可信的反馈,AI超越人类智能只是时间问题。
但“通用超级人工智能”和“围棋超级人工智能”之间有一个重要的区别:
自指
“通用超级人工智能”的智能可以指向自身。一旦自我升级的机制启动,成本便显得无关紧要。
此前有传言称,GPT o3处理ARC问题的成本在200到1000美元之间。如果这个传言属实,OpenAI的战略就变得清晰:成本不是首要考虑,ASI才是关键。初期投入巨资研发成本高昂的ASI,随后利用ASI提升自身效率。
在之前的回答中,有人评论认为这是一种蒸馏手段。其实,这并非蒸馏,而是自指。在复杂系统的研究中,有人提出自复制、自指与自优化的阈值概念。低于这个阈值,系统难免因噪声崩溃;而高于这一阈值,系统便能实现自我升级和修复。
很多人可能会将人类智能的起源追溯到南方古猿,或者某个几千万年前的事件。然而,从上述角度来看,第一种具备自复制能力的生命出现时,人类的智慧便已注定。
我个人认为,当前最困难的仍然是判别器。AlphaGo的判别器相对简单,而AlphaProof则依赖于LEAN。对于一般性问题,判别器是否可靠?我认为这要根据具体情况而定。
在严谨推理的背景下,这一问题可能没有想象中的那么复杂。一些论文专门指出LLM的不足,发现问题后兴高采烈——这可是发表论文的好机会!“逆转诅咒”和“爱丽丝问题”等都是这种类型的研究。但是我想提醒的是,AlphaProof在数学推理上已经超越了人类,而判断逻辑的有效性并不难。只要能转化为LEAN或其他形式化语言,推理便能够得到解决。
更重要的是,许多问题的难易程度并不对称:寻找答案可能很困难,但验证过程却相对简单。推理通常都具备这种不对称特征。
不过,这种不对称性并非处处存在:在事实判断、知识、文化和审美等领域,判别器的可靠性往往不足。在这些方面,ASI的实现恐怕并不容易。
我们日常遇到的大多数问题,实际上是二者的交织:一个简洁的推理框架包裹着复杂的文化背景。
AI的潜力或许并不在推理能力上,而是在文化、语言等一切无法形式化验证的领域。
如何看待deepmind AlphaProof获得2024国际数学奥林匹克竞赛银牌?