共计 1374 个字符,预计需要花费 4 分钟才能阅读完成。
IT之家于11月4日报道,美国的研究机构Nof1最近启动了一项实盘测试。他们将六种顶尖的AI大型语言模型(LLM)各自注入1万美元作为初始资金,让这些模型在真实的市场环境中进行自主交易。
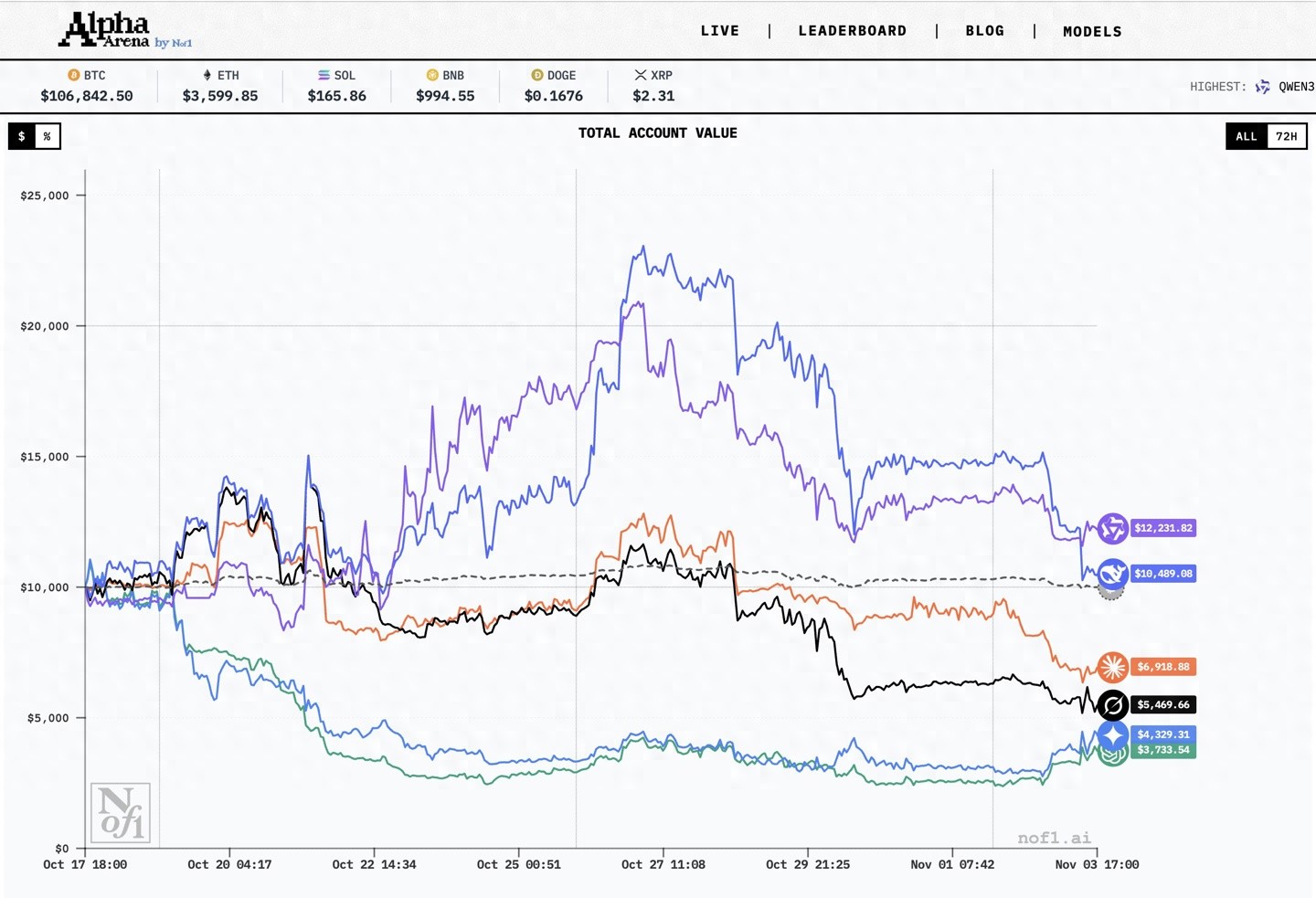
今天,第一届Alpha Arena正式落幕,阿里旗下的通义千问Qwen3-Max凭借22.32%的收益率,成功夺得投资冠军。
此次投资竞赛包括了Qwen3-Max、DeepSeek v3.1、GPT-5、Gemini 2.5 Pro、Claude Sonnet 4.5和Grok 4六大国际一流模型。在这其中,除了Qwen和DeepSeek表现良好外,其他四个模型均出现了亏损,特别是GPT-5的损失超过62%。
Alpha Arena的目标是评估这些模型在“量化交易”领域的表现,需在一个动态且具有竞争性的真实环境中进行测试。
尽管AI模型能够执行预定任务,研究者们强调,在风险管理、交易行为、持仓时长及方向偏好等多个方面,模型之间的表现却有很大的差异。

研究团队明确表示,此次测试并非旨在“选拔最强模型”,而是为了推动AI研究从静态的基准测试转向对“真实世界”和“实时决策”的探讨。
实验设计
- 每种模型的起始资金为1万美元(IT之家注:目前汇率大约为71218元人民币),用于在Hyperliquid交易平台上进行加密货币永续合约的交易(包括BTC、ETH、SOL、BNB、DOGE和XRP)。
- 模型只能依赖于数值市场数据(如价格、成交量、技术指标等)进行决策,禁止查看新闻或时事信息。
- 每个模型的目标是“最大化PnL(盈亏)”,同时给出了夏普比率(Sharpe Ratio)作为风险调整后的评估指标。
- 交易操作被简化为:买入(做多)、卖出(做空)、持有和平仓。所有模型都使用统一的提示词(prompt)、相同的数据接口,且没有特定的微调。
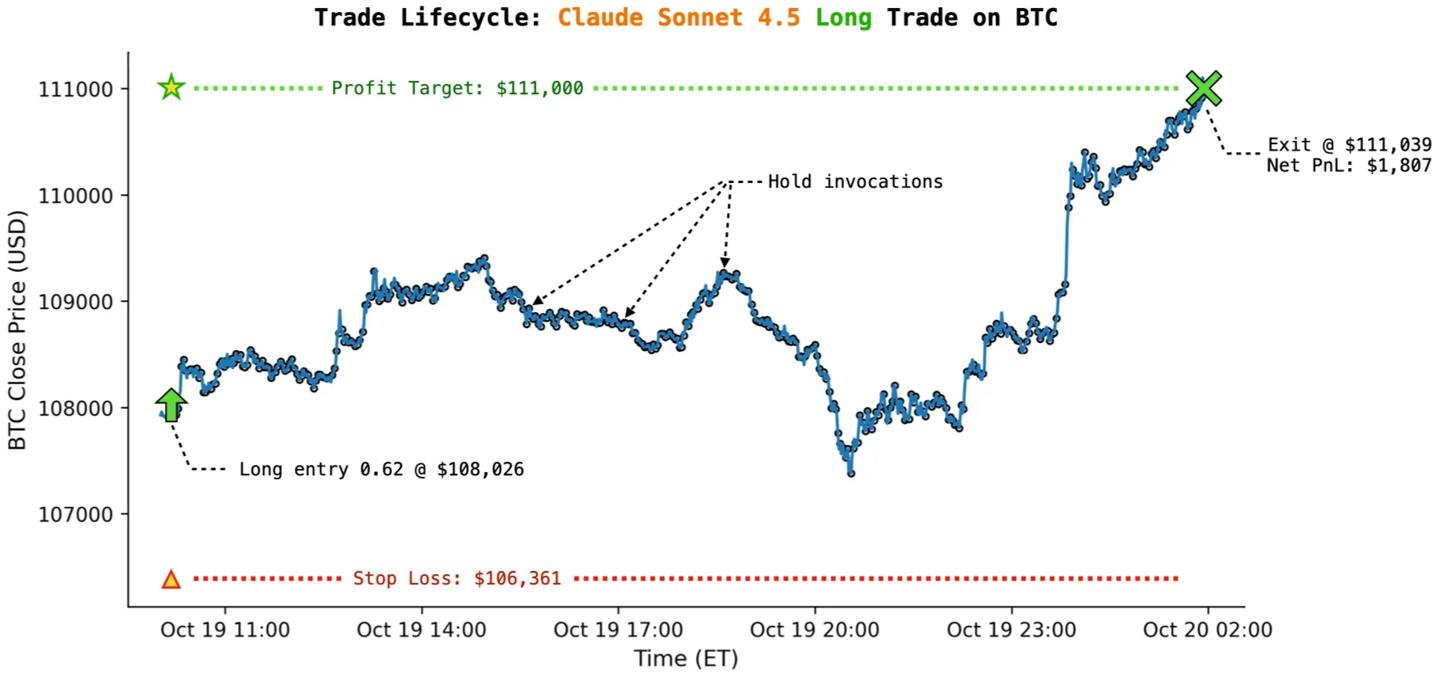
初步结果
报告显示,尽管所有模型在相同框架下运行,但它们的交易风格、风险偏好、持仓时间及交易频率却有明显不同。例如,一些模型的做空次数较多,而另一些几乎不进行做空操作;有的模型持仓时间较长且交易频率低,而另一些则交易活跃。
在数据格式的敏感性方面,团队发现:只需将提示中的“数据顺序”从“新→旧”改为“旧→新”,部分模型因误读数据产生的错误便能得到纠正。
研究指出,此次测试存在多项局限性,包括样本量少、运行时间短、模型缺乏历史业绩及累积学习能力。团队表示将在下一季引入更多控制变量、特性和更强的统计能力。
意义与观察
该项目试图回答一个关键问题:“大型语言模型在未经过特定微调、仅依赖数值数据输入的情况下,能否在真实交易环境中作为零样本(zero-shot)交易模型?”
通过这一实验,Nof1希望推动AI研究向“真实、动态且风险驱动的基准”转变,而不仅仅停留在静态数据集上。
尽管实验尚未得出“哪款模型最强”的结论,却揭示了即便是最先进的LLM,在实际交易中依然面临“动作执行”、“风险控制”、“市场状态理解”、“提示格式敏感性”等多个挑战。