共计 6346 个字符,预计需要花费 16 分钟才能阅读完成。
编辑:Aeneas 好困
【新智元导读】近日,AlphaEvolve再创佳绩!依托其开源实现OpenEvolve,这一系统凭借自我学习与代码编写,迅速在苹果芯片上演进出比人类快21%的GPU核函数!此时此刻,自动化编程史上迎来了真正的里程碑,「AI为AI编程」的新时代已经开启,自动化奇点似乎触手可及。
谷歌的AlphaEvolve,持续不断地书写着新的传奇。
在5月中旬,谷歌引发的这一轰动(被誉为数学界的AlphaGo「第37步」时刻),正在不断挑战公众的认知——AI现已具备了自我进化的能力!
随后,越来越多的开发者通过代码证明了AlphaEvolve矩阵乘法的突破是真实的!一位开发者成功展示,仅用48次乘法就完成了4×4矩阵的乘法运算。
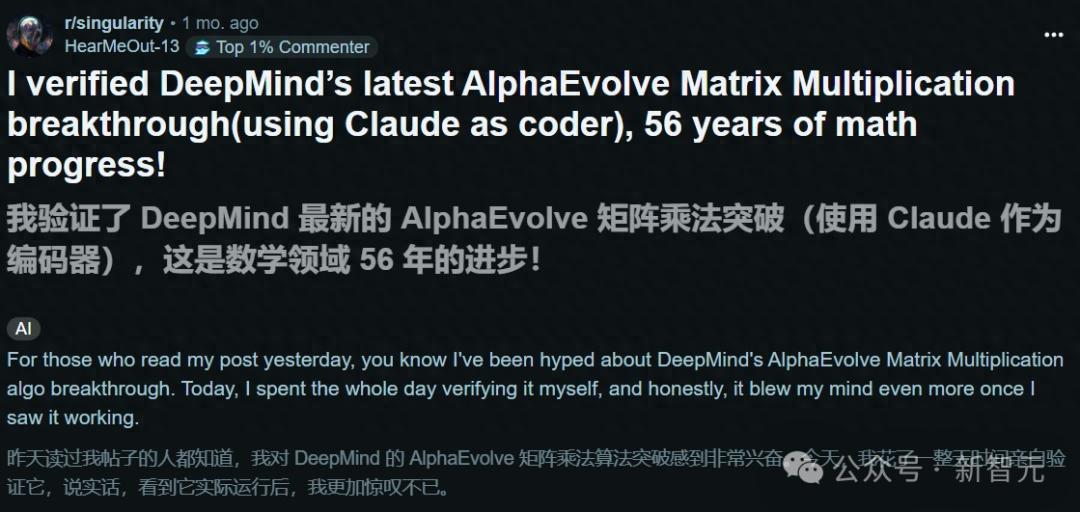
而就在不久前,patched.codes的联合创始人兼CTO Asankhaya Sharma,利用基于AlphaEvolve论文的开源实现OpenEvolve,成功自动识别出高效的GPU内核算法。

具体而言,借助自进化代码,该系统自动识别出了一套在Apple Silicon上显著优于手动优化的GPU Metal内核算法。
在实际的Transformer推理任务中,这一发现实现了平均提升12.5%的性能,最高峰值甚至达到了106%。
这项性能提升,竟然超越了人类工程师21%!

在没有人类GPU编程专业知识的条件下,该系统实现了以下优化——
· 卓越的SIMD优化
· 两阶段在线Softmax处理
· 针对GQA的特定内存布局优化
这不仅仅是一次普通的性能提升,而是自动化编程发展的重要里程碑——一个系统能够在复杂的硬件环境中,自动发现那些连专家都未必能察觉的优化策略,无需人工介入。
更为关键的是,这项成就并不局限于实验室或学术论文,而是在实际应用中,尤其是在苹果的芯片上,针对当前流行的AI任务成功实现。
这充分证明了自动化代码优化技术在现实系统中的有效性。
这一进展象征着一个全新时代的开始:不再是人类为机器编写优化代码,而是机器开始自主生成更优的代码。
随着硬件架构的不断快速演进,像OpenEvolve这样的工具价值将愈发明显——它们能够挖掘出那些人力难以发现的深度优化潜力。

挑战:GPU核函数优化
为何OpenEvolve所面对的「GPU核函数优化」如此具挑战性呢?
原因在于,现代Transformer模型极度依赖于高度优化的注意力核函数,而编写高效的GPU代码则需要深入的专业知识。
· 特定硬件架构的细节(例如Apple Silicon的统一内存和SIMD单元)
· 底层编程语言的掌握(例如Metal Shading Language)
· 数值算法的构建(例如注意力机制、数值的稳定性)
· 优化内存访问策略
因此,是否有可能完全依赖OpenEvolve,而无需人工编写代码,让其自动演化以生成更高性能的GPU核函数代码呢?
为此,Sharma选择了Qwen3-0.6B模型中的分组查询注意力(GQA)作为研究对象,目的是检验OpenEvolve能否自动生成超越MLX生产级的「
scaled_dot_product_attention」核函数的代码。
具体来说,该项目的目标配置如下。
· 模型:Qwen3-0.6B(具备40个查询头和8个键值头)
· 硬件:配备统一内存的苹果M系列GPU
· 基线:MLX的高度优化注意力实现方案
· 挑战:全自动发现Metal核函数的优化策略

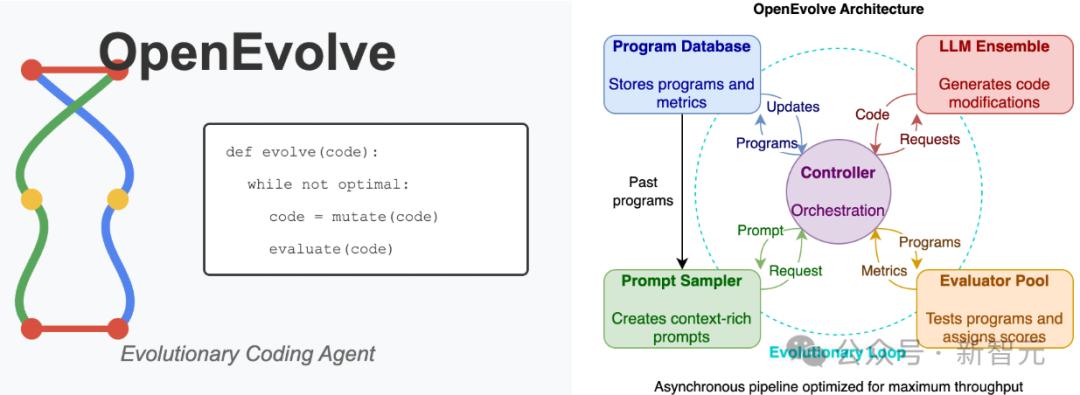
进化方法
OpenEvolve的进化配置与评估方法
Sharma将OpenEvolve系统设计为能够直接优化Metal核函数的源代码,并保持与MLX框架的有效结合。
该系统的进化始于一个基本的三阶段注意力实现,经过25代的持续演化不断完善。

进化参数设置
max_iterations: 25 # 最大迭代次数
population_size: 25 # 种群规模
llm:
primary_model: "gemini-2.5-flash" # 主要模型:用于快速探索 (60%)
secondary_model: "gemini-2.5-pro" # 辅助模型:用于深度优化 (40%)
database:
num_islands: 5 # 岛屿数量:用于并行进化多个种群
evaluator:
bulletproof_mode: true # 启用高强度GPU错误防护模式

评估方法
每一个经过进化而生成的核函数都经过了全面的评估,具体包括以下几个方面:
- 正确性检验:与MLX基线进行数值精度的比较,确保计算结果的准确性。
- 性能评估:在20个多样化的推理场景中进行基准测试(涵盖短/长上下文和生成任务)。
- 安全性评估:包括对GPU错误的检测和Metal内存访问的审核。
- 鲁棒性测试:通过多次重复执行进行的统计分析,以确保性能的一致性。

重要优化措施
令人惊讶的是,OpenEvolve在其进化过程中,意外地发现了一系列突出算法创新的优化策略!
1. 针对Apple Silicon进行的SIMD优化
细心观察,我们会发现OpenEvolve的一个亮点,就是它巧妙地识别了一个非常有效的优化方案——
对于128维的注意力头,将数据按8个一组处理,恰好能完全适配Apple Silicon硬件的SIMD宽度。
这就如同自动进入了硬件的“甜点区”,无需任何手动调优,便能将性能提高到极致,最大化硬件的利用效率!
2. 两阶段在线Softmax(Two-Pass Online Softmax)
提升计算效率的创新方案
// 第一步:在线获取最大值,以确保数值稳定性
T max_score = T(-INFINITY);
for (uint key_pos = 0; key_pos output_acc_v[HEAD_DIM / 8];
for (uint key_pos = 0; key_pos *)(values + v_base))[d_vec];
}
在这个过程中,OpenEvolve进行了一个非常巧妙的设计:将原本分开的Softmax归一化和值的累加合并为一个计算循环。
通常情况下,传统算法需要经历三个步骤:首先计算注意力得分,接着进行归一化,最后再加权求和。
而如今只需两个步骤就能完成,整个流程显得更加简洁,同时显著减少了对内存带宽的消耗,从而提高了运行速度和资源的使用效率。
3. 针对GQA的内存布局优化策略
// 针对GQA的查询头与键值头比例为5:1,进行直接映射
const uint kv_head_idx = head_idx / HEADS_PER_KV; // 精妙的头映射策略
// 实现合并内存访问模式
const uint q_base = batch_idx * (NUM_HEADS * SEQ_LEN * HEAD_DIM) +
head_idx * (SEQ_LEN * HEAD_DIM) +
query_pos * HEAD_DIM;
在这方面,OpenEvolve的一个创新之处在于,特别针对Qwen3模型的独特架构进行了优化。
该模型的查询头与键值头的比例为40:8,即5:1,系统充分发挥了这一特性,设计了一种独特的合并内存访问模式。
这种模式特别适合Apple Silicon的统一内存架构,简直是量身定制,带来了极高的效率和性能。

性能评测结果
性能飞跃:新核函数的卓越表现
不出所料,最终演变而成的核函数在各类综合基准测试中,展现了明显的性能优势:

关键性能指标的提升
- 解码速度(Decode Speed):平均提升达+12.5%(标准差σ = 38.3%)
- 预填充速度(Prefill Speed):平均提升达+14.4%(标准差σ = 17.6%)
- 总吞吐量(Total Throughput):平均提升达+10.4%(标准差σ = 30.7%)
- 内存使用量(Memory Usage):平均降低达+0.99%(标准差σ = 1.7%)
- 正确性(Correctness):保持了100%的数值精度
- 可靠性(Reliability):无任何GPU错误或核函数崩溃现象

基准测试结果详解

在重复性模式生成任务中,OpenEvolve所使用的核函数实现了速度提升高达106%!
这一结果清楚地表明,该核函数在处理特定工作负载时,确实展现了卓越的性能。

数据统计分析
综合统计结果显示,OpenEvolve在特定工作负载中展现了显著的优化潜力,能够挖掘出手动编码难以达到的性能优势。
在20项不同的测试任务中,其中7项任务的性能提升显著,增长幅度超过25%,展现了“质的飞跃”。
- 显著提升(>25%):7/20项基准
- 中等提升(5-25%):3/20项基准
- 性能持平(±5%):4/20项基准
- 性能下降(<-5%):6/20项基准测试
- 命令缓冲区的防护:能够自动检测Metal命令缓冲区中的错误并加以恢复。
- 内存访问违规的处理:安全地管理GPU内存访问中的违规情况。
- 重试机制:针对瞬间的GPU错误提供指数退避的重试方案。
- 回退机制:在核函数遇到严重问题时,能够优雅地切换到备用方案。
性能回落的背后:不可忽视的关键因素

关键推动力:强大的鲁棒性评估系统
值得注意的是,该项目的成功离不开OpenEvolve背后强大的评估系统。
这不仅是一个简单的性能测试工具,而是专门为GPU核心函数设计的,旨在克服开发过程中遇到的各类挑战。

GPU的安全特性

全面的错误统计

技术深度剖析

面向GPU核函数的进化架构
项目的成功离不开OpenEvolve中各个组件的紧密协作:
- 智能代码标记:通过特定的标记,确保进化过程仅专注于Metal核函数的源代码,同时完整保留与MLX框架相关的集成代码。
# EVOLVE-BLOCK-START
kernel_source = """// 仅此块内的Metal核函数代码会被进化"""
# EVOLVE-BLOCK-END
- 富含上下文信息的提示词:这些提示词提供了关于性能数据、硬件规格和优化方向的指导。
- 多目标评分机制:在性能、正确性和安全性等多个目标之间进行平衡与评分。
- 特定硬件验证:所有的测试与优化均针对Apple Silicon硬件进行。

面向GPU的优化提示词工程
同时,进化过程中的提示词为OpenEvolve提供了至关重要的上下文信息:
关于硬件特性与优化目标的深度分析
在当前技术环境下,Apple Silicon M系列的GPU采用了统一内存架构,带来了极大的便利。其最佳的SIMD宽度被设定为8个元素,适合用于vec类型数据。而在硬件占用方面,32线程的线程组大小被认为是最理想选择,以此实现最高的资源利用率。
优化目标的设定
为了提升整体性能,主要优化目标包括:减少内存带宽的使用、最大化SIMD指令的执行效率、充分利用GQA模型的40:8头结构特性,并确保数值计算的稳定性。这些目标为后续的技术改进提供了明确的方向。
当前性能基准
目前的解码速度已达到每秒140.6个token,为了实现更优的性能,目标设定为需提升超过5%。这一提高不仅能够增强处理效率,还对优化策略提出了更高的要求。

深远的影响
综上所述,针对GPU核函数的优化取得了显著成果,揭示了几个关键原则:
1. 自动化探索与专业知识的结合
OpenEvolve所发现的优化策略,涵盖了多个需要深入专业知识的领域:
- Apple Silicon架构的细节分析
- Metal编程语言的独特优势
- 注意力算法的多种变体
- 内存访问模式的优化方法
这些知识并非单纯由工程师提供,而是在演化过程中自我涌现的结果。
2. 针对特定硬件的自适应优化
Apple Silicon硬件的量身定制优化与算法创新
最终的优化方案专为Apple Silicon硬件设计,这意味着OpenEvolve能够自动探测并有效利用该硬件的独特特性。
3. 算法创新的突破
在进化过程中,发现了名为“两阶段在线Softmax”的算法,这一技术本身是一项颇具创新性的贡献,其应用潜力已超出当前实验所涵盖的特定场景。
4. 具备实际应用的潜力
这些优化并非纸上谈兵,而是能在实际的Transformer推理负载中显著提升性能的实用技术,完全适合于生产环境的部署。

核心技术架构的提升
自项目启动以来,Sharma对OpenEvolve的核心功能进行了显著的改进:
- 可复现性(Reproducibility)
通过完全确定性的进化流程,确保科研级别的可复现性。
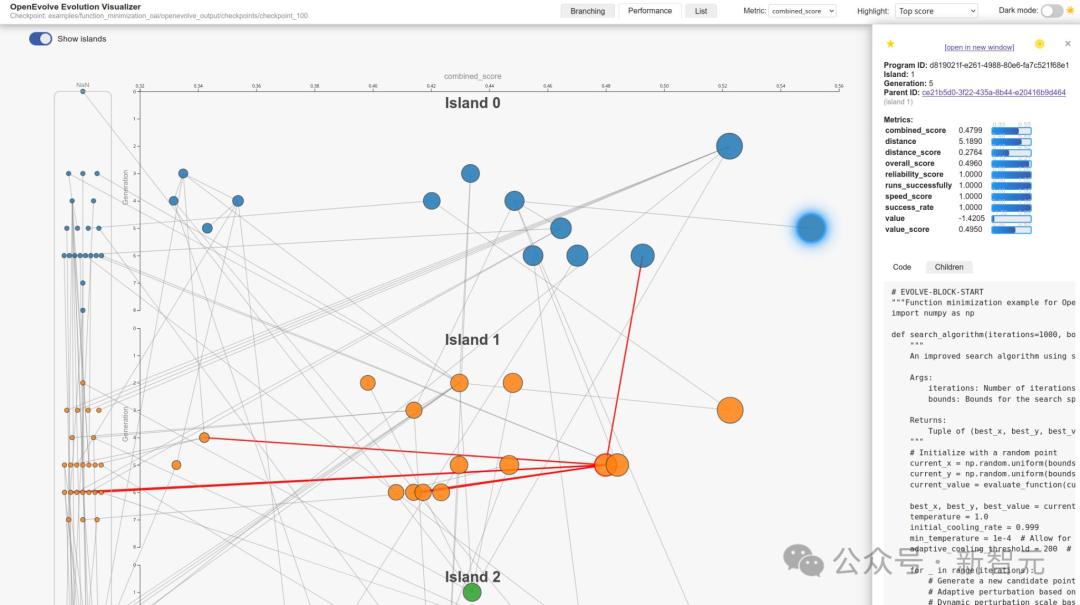
random_seed: 42 # 确保每次运行结果完全一致- 可视化(Visualization)
提供交互式的进化树视图,能够支持实时性能监测。
探索岛屿进化:并行优化的全新视角
在科学研究中,借助种群的迁徙可以实现高效的并行进化,进而提升解空间的探索能力,这是一个极具创新性的理念。
数据库设置:
岛屿数量: 5
迁移间隔: 25
健壮的检查点机制可确保在进化过程中,系统能够自动保存进度,并在出现中断时顺利恢复,这对于维护实验的连贯性至关重要。

迅速入门
那您是否已经准备好迎接GPU核函数优化或其他复杂问题的挑战呢?
只需输入以下指令,即可迅速展开您的探索之旅:
# 克隆代码库
git clone https://github.com/codelion/openevolve.git
cd openevolve
# 安装所需依赖
pip install -e .
# 运行MLX核函数优化示例
cd examples/mlx_metal_kernel_opt
python openevolve-run.py initial_program.py evaluator.py --iterations 25
如果您希望获取更多详细信息,建议您仔细阅读以下文档,以便深入理解相关内容。

GPU内核优化的完整指南可访问:https://github.com/codelion/openevolve/tree/main/examples/mlx_metal_kernel_opt
通用的学习资料请查看:https://github.com/codelion/openevolve#getting-started

有关配置的详细信息请访问:https://github.com/codelion/openevolve/tree/main/configs
参考链接:
探索GPU内核发现的全新视角了解更多有关配置的信息,请访问以下链接:这里。