共计 4584 个字符,预计需要花费 12 分钟才能阅读完成。
【导读】就在刚刚,AlphaEvolve再创辉煌!依托其开源实现OpenEvolve,该系统凭借自我学习和自主编程,竟在苹果芯片上开发出比人类快21%的GPU核心函数!这一时刻,标志着自动化编程史上的重要里程碑,真正开启了「AI为AI编程」的新纪元,自动化的奇点似乎真的要到来了。
谷歌的AlphaEvolve,持续不断地带来惊喜。
在5月中旬,谷歌发布的这一重磅消息(被誉为数学界AlphaGo的「第37步」时刻),持续冲击着人们的认知——AI已经具备了自我进化的能力!
紧接着,开发者们纷纷用代码验证了AlphaEvolve在矩阵乘法上的突破!一位开发者成功地证明,仅用48次乘法就完成了4×4矩阵的乘法运算。
而就在此刻,patched.codes的联合创始人兼首席技术官Asankhaya Sharma,基于AlphaEvolve的研究论文,运用开源实现OpenEvolve,成功自动发现了高效的GPU内核算法。


具体而言,凭借自我进化的代码,该系统自动发现了一组在Apple Silicon上性能远超人工优化的GPU Metal核心函数。
在实际的Transformer推理任务中,带来了平均12.5%的性能提升,峰值更是飙升106%。
这一成果,直接超越了人类工程师21%!

该系统无需依赖人类的GPU编程专业知识,便发现了以下优化方案——
· 完美的SIMD优化
· 两阶段在线Softmax
· 针对GQA的特定内存布局优化
这并非简单的性能提升,而是自动化编程发展史上的真正里程碑——一个系统无需人类干预,便能在复杂的硬件架构中,挖掘出连专家也难以觉察的优化路径。
机器自主优化代码的新时代:OpenEvolve的突破更为关键的是,这一创新成果并非局限于学术界或实验室,而是实实在在地在苹果芯片上、在当下流行的人工智能模型任务中得到了验证。
这充分展示了自动化代码优化技术在实际系统中的有效性。
这一成就象征着一个全新时代的开启:机器不再依赖人类手动优化,而是开始自主生成更高效的代码。
随着硬件架构的快速演进,像OpenEvolve这样的工具将显得愈发重要——它们能够挖掘出那些人力难以识别的深层次优化机会。
挑战:GPU核函数的优化难题
那么,为什么OpenEvolve所面对的「GPU核函数优化」任务如此富有挑战性呢?
原因在于,现代Transformer模型高度依赖于精细调优的注意力核函数,而编写高效的GPU代码需要掌握以下几个专业领域的知识。
· 特定硬件架构的细节(如Apple Silicon的统一内存、SIMD单元)
· 底层编程语言(如Metal Shading Language)
· 数值算法设计(如注意力机制、数值稳定性)
· 内存访问模式的优化
那么,是否存在一种可能性,使得我们可以将代码的编写完全交给OpenEvolve,让其自动进化,以生成性能更优的GPU核函数呢?
因此,Sharma决定以Qwen3-0.6B模型的分组查询注意力(GQA)作为目标,来评估OpenEvolve的能力,看它是否能够自动生成超越MLX的生产级「
scaled_dot_product_attention」核函数的代码。
具体而言,项目的目标配置如下。
· 模型:Qwen3-0.6B(40个查询头 : 8个键值头)
· 硬件:配备统一内存的苹果M系列GPU
· 基线:MLX的高度优化的注意力实现方案
· 挑战:全自动发现Metal核函数的优化方法
进化方法
Sharma将OpenEvolve配置为直接进化Metal核函数的源代码,同时保留其与MLX框架的集成方式。
整个系统始于一个基础的三阶段注意力实现方案,经过超过25代的进化。
进化设置

评估策略
每一个通过进化生成的核函数都经过了以下几个方面的全面测试:
- 正确性验证:与MLX基线进行数值精度对比,确保计算结果无误。
- 性能测试:在20个多样化的推理场景(包括短/长上下文、生成任务)中进行基准测试。
- 安全性检查:包含GPU错误检测和Metal内存访问验证。
- 鲁棒性分析:通过多次重复运行进行统计分析,以确保性能的稳定性。
关键优化
出乎意料的是,OpenEvolve在进化过程中,自行发现了几项体现出算法创新的优化策略!
1. 针对Apple Silicon的SIMD优化

通过仔细观察,我们可以看到,OpenEvolve的一个显著亮点是自主识别出了一种非常巧妙的优化方案——
对于128维的注意力头,若将数据按8个一组处理,正好能够完美匹配Apple Silicon硬件的SIMD宽度。
这就如同自动找到了硬件的「最佳区域」,无需任何人工调整,性能即可达到最佳,让硬件的利用率得以最大化!
2. 两阶段在线Softmax(Two-Pass Online Softmax)
OpenEvolve的创新突破:性能提升与内存优化
在推进过程中,OpenEvolve展现出一种独到的创新思维:将原先分开的Softmax归一化和加权求和两个步骤,巧妙地合并为一个计算循环。
以往,传统算法需要经历三个阶段:首先计算注意力得分,然后进行归一化,最后再进行加权求和。
如今,这一过程简化为两步,显著提高了效率,同时也大幅度减少了内存带宽的消耗,因此在运行速度和资源利用方面都有了显著改善。
针对GQA的内存布局优化
在这方面,OpenEvolve的创新体现在专门为Qwen3模型的独特结构进行的优化设计。
该模型的查询头与键值头的比例为40:8(即5:1),系统充分发挥这一特性,设计出一种独特的合并内存访问模式,称为Coalesced Memory Access。
这种模式特别契合Apple Silicon的统一内存架构,效率极高,性能表现可谓是量身定做。
评测成果
最终生成的核函数在各项综合基准测试中,果然展现出显著的性能提升:
核心性能指标提升
- 解码速度(Decode Speed):平均提升12.5%(标准差σ = 38.3%)
- 预填充速度(Prefill Speed):平均提升14.4%(标准差σ = 17.6%)
- 总吞吐量(Total Throughput):平均提升10.4%(标准差σ = 30.7%)
- 内存使用量(Memory Usage):平均降低0.99%(标准差σ = 1.7%)
- 正确性(Correctness):保持100%的数值精度
- 可靠性(Reliability):零GPU错误或核函数崩溃
详细基准测试结果
在重复性模式生成任务的处理上,OpenEvolve进化生成的核函数更是将解码速度提升了惊人的106%!
这无疑证明了该核函数在应对特定工作负载时,性能表现出色。
统计分析
综上所述,从统计数据来看,OpenEvolve在特定类型的工作负载上展现出了强大的优化能力,能够挖掘出原本手写代码无法触及的性能潜力。
在20个不同的测试任务中,有7个任务显示出明显的提升,性能增长超过25%,体现了质的飞跃。
显著增益(>25%):7/20个基准
中等增益(5-25%):3/20个基准
性能持平(±5%):4/20个基准
性能回退(6/20个基准):
成功背后的关键:高鲁棒性评估系统
值得注意的是,这一项目的成功离不开OpenEvolve背后的评估系统。
它并非普通的跑分工具,而是为GPU核函数这种高强度代码而特别设计,旨在应对GPU核函数开发过程中面临的各种挑战。
GPU安全特性
命令缓冲区保护:自动检测Metal命令缓冲区的错误并进行恢复。
内存访问违规处理:安全处理GPU内存访问违规。
重试逻辑:为瞬时GPU错误提供指数退避重试机制。
回退机制:当核函数彻底失败时,能够优雅地降级到备用方案。
全面的错误统计

正是由于这套评估体系的高度稳定与强大的鲁棒性,使得OpenEvolve能够大胆探索多种激进的优化方案,而无需担忧“越改越崩”的风险。
值得注意的是,GPU核函数作为一种实验性代码,极易出现错误,哪怕是微小的问题也可能导致整个程序崩溃。
因此,拥有这样一个高鲁棒性的保障机制,才能使系统在不断创新中,逐步提升性能,尝试新的可能性。
技术深度解析
面向GPU核函数的进化架构
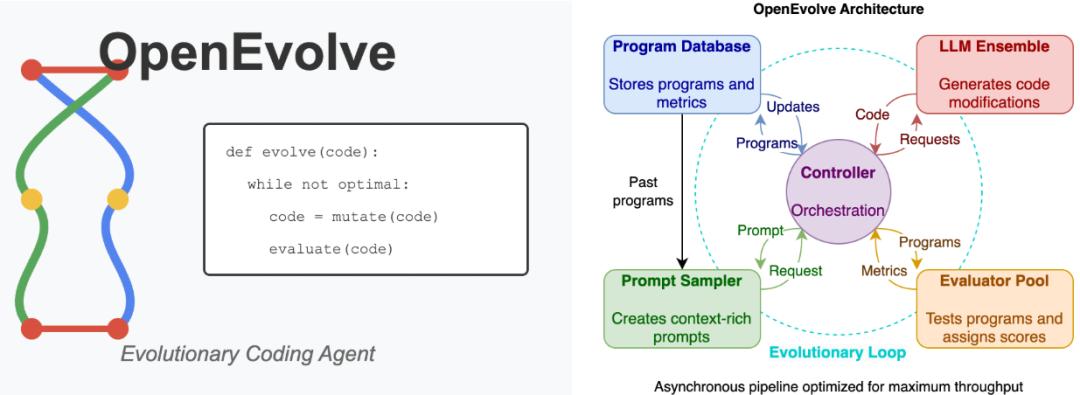
此外,该项目的成功离不开OpenEvolve中众多组件的协同作用:
- 智能代码标记:通过特定标记,确保进化过程仅针对Metal核函数源代码,同时完整保留与MLX框架的集成代码。

- 富含上下文信息的提示词:为进化过程提供的提示词包含了性能数据、硬件规格和优化方向指南。
- 多目标评分机制:在性能、正确性和安全性等多个目标之间进行权衡评分。
- 特定硬件验证:所有测试和优化都针对Apple Silicon硬件进行。
面向GPU优化的提示词工程
与此同时,提供给进化过程的提示词也为OpenEvolve提供了至关重要的上下文信息:

更深远的影响
综上所述,这次对GPU核函数的成功优化,揭示了几个重要的原则:
1. 专业知识的自动化探索与发现
OpenEvolve所发现的优化策略,涵盖了多个需要扎实专业知识的领域:
- Apple Silicon的架构细节
- Metal编程语言的精妙之处
- 注意力算法的各种变体
- 内存访问模式的优化
这些专业知识并非由人类工程师直接提供,而是在进化探索的过程中自然涌现的。
2. 面向特定硬件的自适应优化
最终的优化方案是专为Apple Silicon硬件设计的,这表明OpenEvolve能够自动发掘并利用特定硬件的特征。
3. 算法层面的创新
进化过程中发现的“两阶段在线Softmax(two-pass online softmax)”算法,实际上是一项新颖的技术贡献,其应用潜力远远超出本次实验的特定场景。
4. 具备投产应用的价值
这些优化并非只停留在理论层面,而是在实际的Transformer推理负载中能够显著提升性能的实用技术,完全具备在生产环境中部署的价值。
核心技术架构升级
自项目启动以来,Sharma对OpenEvolve的核心能力进行了显著的提升:
可复现性(Reproducibility)
通过完全确定性的进化过程,确保科研级别的可复现性。
可视化(Visualization)
提供交互式的进化树视图,支持实时性能监控。
岛屿进化(Island Evolution)
通过种群迁移实现并行进化,以增强解空间的探索能力。

强大的检查点机制
该机制能够自动保存进度,并从中断的地方恢复进化会话。
快速上手
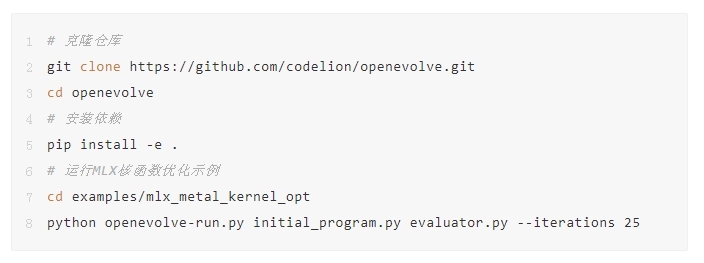
那么,你是否已准备好亲自体验,迎接GPU核函数优化等复杂挑战呢?
只需输入以下代码,便可迅速开始:
若想获取更详尽的内容,建议仔细阅读以下文档。

GPU内核优化手册:
https://github.com/codelion/openevolve/tree/main/examples/mlx_metal_kernel_opt
通用指南:
https://github.com/codelion/openevolve#getting-started

配置指南:
访问链接获取更多信息:配置参考
附加资料:
了解更多请参考:相关博客
本文由微信公众号“新智元”提供,编辑:Aeneas 好困,经过36氪授权发布。