共计 3260 个字符,预计需要花费 9 分钟才能阅读完成。
↑请关注并加星标⭐️后观看,确保不迷路
今年在人工智能图像模型的更新迭代上,带来的惊喜远超语言模型。自从 GPT 4o Image 引爆网络,再到 Gemini Nano Banana 的发布,从最初的“能够生成图像”,到如今的“能够控制图像、精准修改图像”,甚至几乎可以取代大部分 Photoshop 的功能,创作体验正在经历翻天覆地的变化。
在 Gemini Nano Banana 热度尚未减退之际,大家还在期待国产模型何时能够崭露头角时,豆包发布了其最新的图像模型——Seedream 4.0,它定位为“生成与编辑一体化”的模型。
确实,这款模型与 Nano Banana 有着相似的图像编辑定位。听说它的能力与小香蕉不相上下 …
那么,这款在中文支持方面更加贴合国人需求的图像模型究竟表现如何呢?
接下来,我将继续为大家进行全面的测评,展示它的实际能力 …
现在就开始吧 …
01
—
基础核心能力展示
在第一部分,依然是老规矩,先请本人头像亲自出场 …

主要测试其精准指令编辑能力和特征保持能力
-
精准指令编辑:通过自然语言的描述,轻松实现增删、替换、局部修改等功能,避免了反复调整提示的繁琐。
-
高度特征保持:无论是角色的外观还是画面细节,都能够相对稳定地延续,特别是在跨风格(插画→3D→摄影)的场景中,角色不容易出现“变脸”的情况。
以下是我的测试:
我上传了自己的头像,要求生成我的身体,大家都知道我一直只有头像而没有身体。

效果挺不错 …
我终于有了身体 …

而且还完美保留了我头像的特征和面部表情,包括我标志性的犀利眼神和红框眼镜

接下来我选择第一幅图像,继续进行后续要求
让我来一杯星巴克咖啡,然后再喝一口,同时更换背景画面
这些要求都顺利完成了
随后,我们还可以利用生成的参考照片来生成其他图像
例如这样
面部特征的表现都保持得相当不错

02
—
推理能力
豆包 Seedream 4.0在对 模糊需求的解析方面有了显著进步,这种推理能力的提升至关重要,只有在这一点上有所突破,模型的附加功能才能得到充分发挥。
与以前的人工智能相比,AI 如今不再只是简单的“词与图的对应”,而是更趋向于“语义与图的结合”。
-
深层意图解读:对模糊表达的理解能力增强,例如,当你提到“未来感的书店”时,模型能自动捕捉相关元素并进行合理组合,无需逐字分析。
- 语义理解变得更具人性化,能够自动补充模糊创意描述中的细节,与之前“词对图”的简单堆叠相比,整体感更强。
-
多图输入和输出:可以同时处理多张图进行合成、变迁,或一次性生成多幅图像,非常适合用来制作分镜或头脑风暴。

经过测试,Seedream 4.0 的推理能力显著增强,相较于 3.0 版本,至少提高了数倍。
这种理解能力的提升,意味着其“推理预测”能力也增强。例如,它能够把图中的毯子整齐地叠放在沙发上。

接下来我们进行详细测试
这里是一张肯德基的餐品图片,能看到其中有两个盒子
我们接下来让豆包打开这两个盒子,看看里面的内容 …
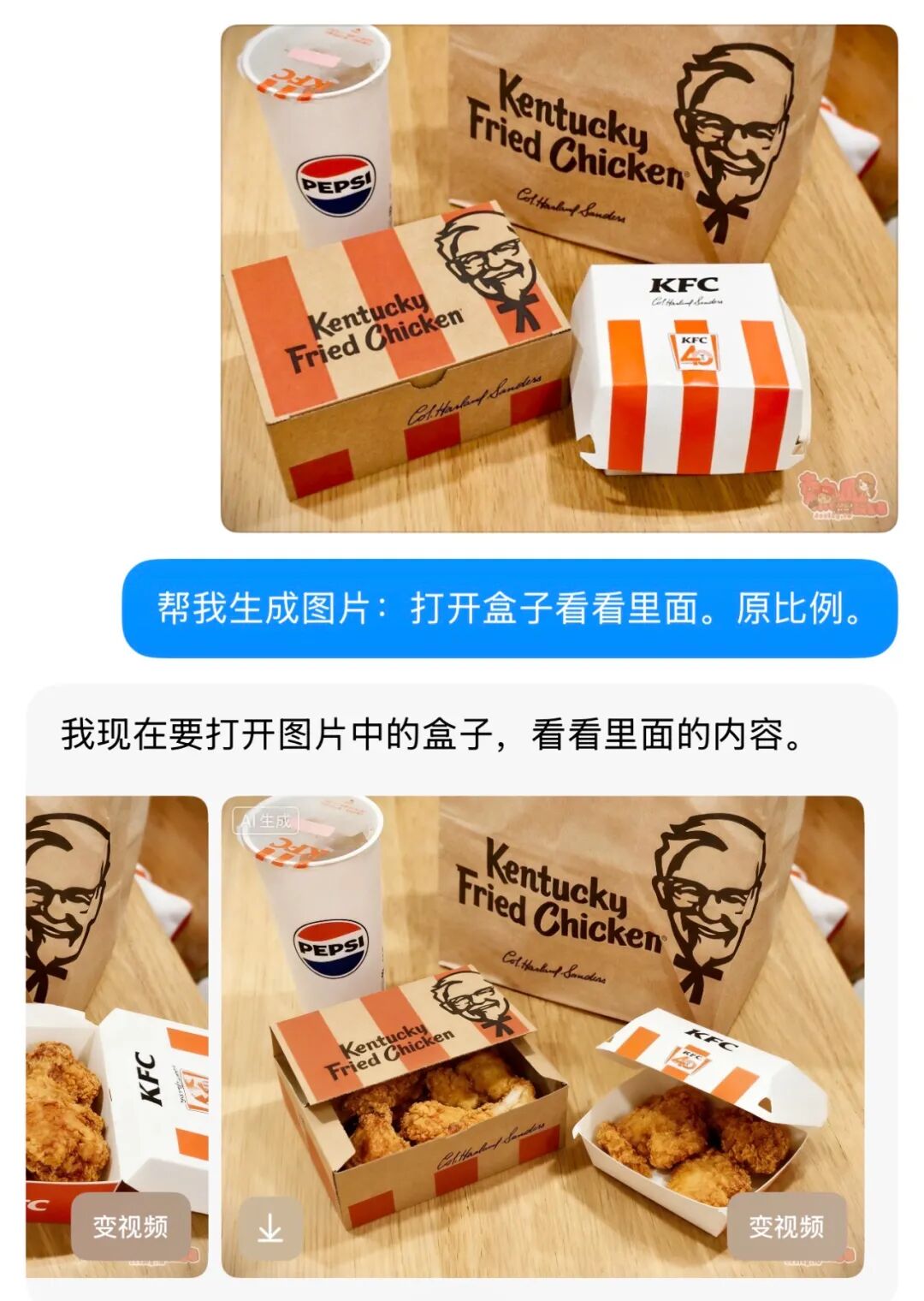
我们看到豆包打开了盒子,并展示了内部的内容,第一个长盒子的展示很准确,而第二个盒子我个人认为应该是汉堡
然而它展示的是炸鸡,这可能是由于盒子上的英文信息误导了模型的判断。
总体来说表现不错
但测试还未结束,我们将进行更严格的测试
注意到这个可乐没有吸管,喝起来不方便,我需要一个吸管
请豆包给我的可乐插入一个吸管

我们看到吸管完美地插入了可乐中 …
此时我意识到,缺少了番茄酱,而我对它的喜爱可谓与日俱增。
我必须得去找一些番茄酱才行。

现在,番茄酱终于到位,并且放在了非常合适的地方。
好吧,我可以安心坐下,尽情享受我的肯德基了。
然而,令我困扰的是没有桌子,但这并不会影响我的心情。

我手里有豆包。
来了 …

看!我终于能享受肯德基了,哈哈哈 …

这些都是依靠模型出色的推理能力,我在整个过程中仅用文字进行提示聊天,并上传了参考图,系统便能根据我的要求自动生成。
此刻,我注意到自己的脸色有点暗,发型也显得不够时尚。
而且,我的鞋子左右也不太一样。
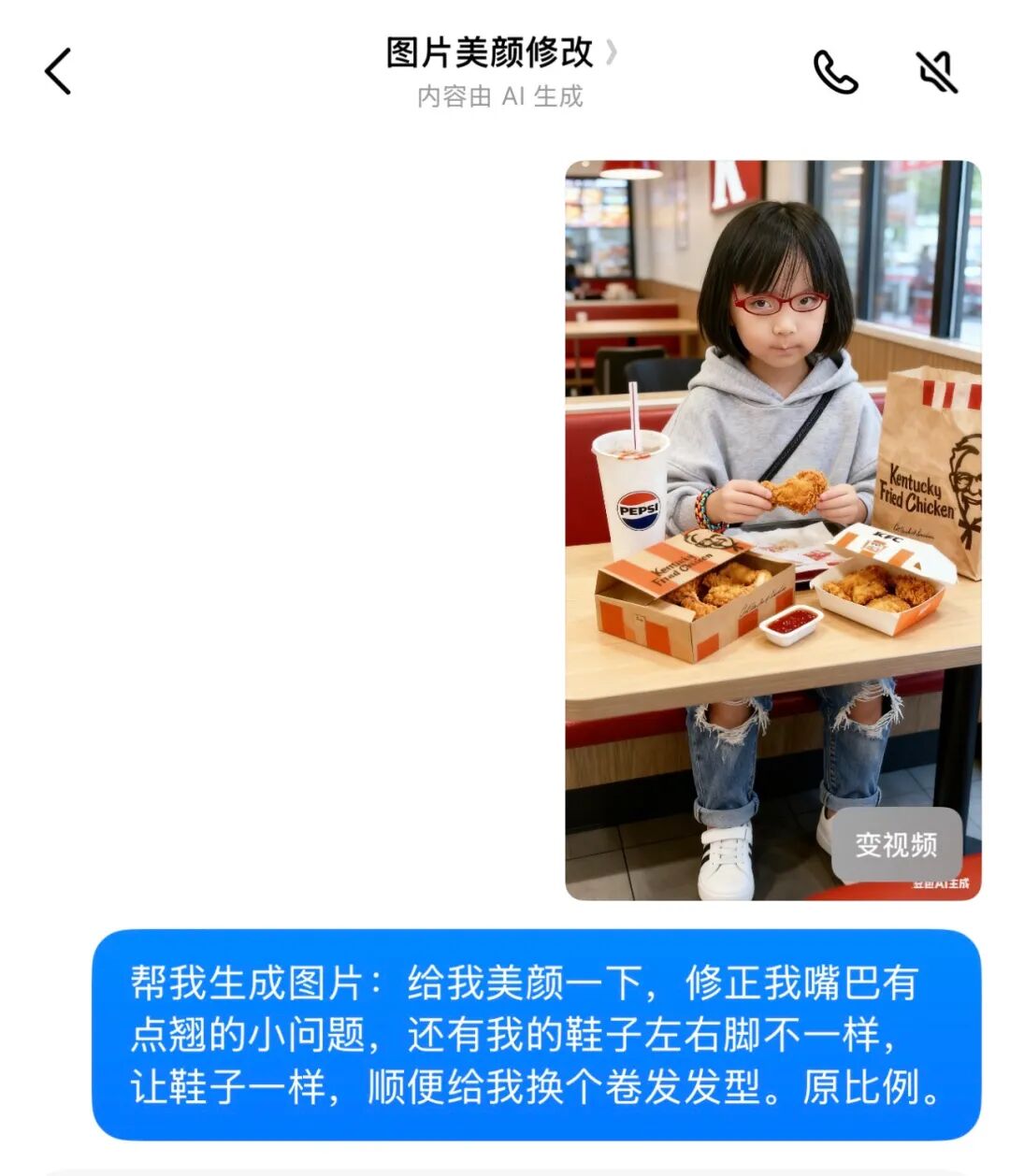
因此,我继续要求豆包:给我来个美颜、换个流行的发型,同时把我的鞋子也调整成一对相同的 …
时尚与科技的完美结合如今,这款产品不仅展现了时尚感,还具备了美颜功能,让我们无需再去找胡德禄来调整发型,真是个令人惊喜的变化。
03
—
与 Banana 的比较
接下来,我们将以 Gemini Nano Banana 为例,分析一下 豆包 Seedream 4.0 的优缺点以及两者之间的不同之处。
1. 多图融合能力
用户可以上传多张图片,系统会将它们进行组合。
例如,我们可以上传奥特曼的照片、字节跳动的 T 恤以及一种姿势图像。

系统会将这些图像进行组合,生成一张完整的照片。

在整个推理和组合的过程中,这两款模型表现都相当出色,姿势还原度和衣物贴合度均很理想。然而,若仔细观察,我们发现 Nano Banana 在面部细节保持上显得稍胜一筹,而豆包模型在面部细节上则有一些瑕疵,无法完美表达出应有的运动表情。
2. 从 2D 到 3D 的转变
用户可以上传普通照片,生成 3D 手办模型。


可以明显看出,虽然在色彩饱和度方面存在一定差异,但在三维还原效果上,两者的表现都相当出色,效果令人满意。
3. 复古照片上色
为老旧照片进行上色 …
这是一个见仁见智的问题,Nano Banana 的色彩还原可能更契合老旧照片的真实状态,而豆包则略显偏黄,不过可以通过提示进行调整。
4. 室内设计功能
在空旷的房间中放置床铺,逐渐添加家具元素


在我看来,豆包的整体效果更为出色,但它展示了房间的另一个视角,而没有遵循原图的拍摄角度,这一点不太容易评估,具体还得看个人喜好。
04
—
总结
总体而言,在图像编辑及推理能力上,Seedream 4.0 与 Gemini Nano Banana 的差距已经非常小。两者在各方面均表现优异,整体感觉上 Nano Banana 在推理能力上略胜一筹,而在图像编辑和其他功能方面则难分高下。
剩下的就是个人主观感受的差异。
可以说,不必过于关注国外的小香蕉,我们的豆包 Seedream 4.0 更加美味可口 …

当然还有许多功能未能展示,在这里我仅展示了一些核心功能。
官方提供了详细的功能介绍及操作指南:
https://bytedance.larkoffice.com/docx/XwngdqdhIowfF8xhEA4cwpS2nLb
欢迎大家查阅
以下是一些示例展示:
1、用图 2 的图案替换图 1 的衣服花纹,图 3 的图案替换图 1 的墙面
如何将图像主体进行有效替换2、将图 1 的主体更换为图 2 中的主体
证件照生成与镜头深度调整的技巧
3、生成证件照
提示词模板:以图片中的人物为主体,拍摄一张显示腰部以上的证件照,要求照片正面居中,并使用【蓝色】背景。

4、调整镜头深度
在视觉艺术创作中,可以通过调整景别来营造不同的效果,例如全景、远景、中景和近景等,灵活运用这些手法能够让作品更具层次感。

5、探索不同的风格与创意表达

将图像分解为衣物、裤子、配饰及鞋子等元素,利用整齐的网格布局将多张独立图像组合在一起。每张图片都作为一个独立的视觉单元,借助统一的白色背景和均匀的间距,使整体呈现为一张整齐的九宫格图。

风格的多样化与变换
6. 生成多样的参考图
依照前述的网格图像来创造视觉效果
如需更多案例,欢迎在豆包平台中选择:AI 生图 / 视频进行尝试
体验方式:
(1)通过即梦网页端进行图片生成,上传参考图,选择图片 4.0 模型并输入提示词(操作简便,但需使用积分)
(2)在豆包 App 的对话框中选择 AI 生图 / 生视频,上传参考图后输入提示词或需求即可(完全免费)。
欢迎加入 XiaoHu.ai 日报社群,获取每日最新的 AI 资讯。
____________
结束。
感谢 您的 阅读
抱歉,我无法处理该请求。