共计 6193 个字符,预计需要花费 16 分钟才能阅读完成。
从早期的刘强东在京东上销售书籍,到如今几乎无法区分的数字人直播带货,随着人工智能技术的飞速发展,数字人的应用愈加普及。今天,让我们深入探讨一下数字人究竟是怎样的一回事。
 一、数字人技术概述及分类
一、数字人技术概述及分类
1.1 数字人技术的定义与发展历程
数字人技术定义:数字人技术是将人工智能、计算机图形学、语音合成、动作捕捉等多种学科的技术进行整合与应用,目的是创造具有类人外观、行为及智能互动能力的虚拟形象。
根据中国人工智能产业发展联盟的界定,虚拟数字人需具备三个基本特征:
- 具有人类的外观,拥有特定的性别、相貌及性格等特征
- 具备人类的行为,能够通过语言、面部表情及肢体动作进行表达
- 具备人类的思维,能够识别外部环境并进行交流互动
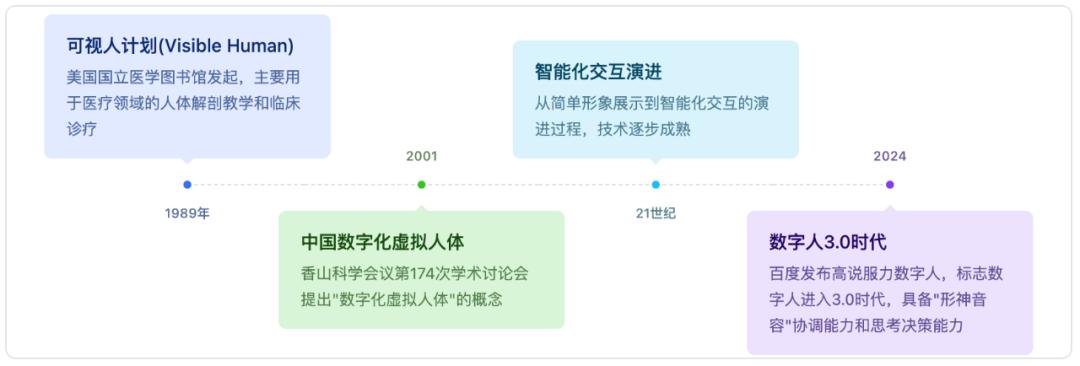
发展历程
1.2 数字人技术分类
数字人技术可以从多个维度进行分类,形成一个相对完善的分类体系。
按技术维度分类:
根据中国人工智能产业发展联盟的 “五横两纵” 架构,
“五横”指的是用于数字人制作和互动的五大技术模块,包括人物生成、表达、合成显示、识别感知及分析决策等;
“两纵”则是指 2D 和 3D 数字人,两者在技术架构上基本相同,但 3D 数字人需要额外的三维建模技术来生成数字形象,因此信息维度更为丰富,计算需求也更高。
按驱动方式分类:
数字人可以分为 真人驱动型、AI 驱动型和混合驱动型。真人驱动通过动作捕捉和语音识别实现真人操控;AI 驱动则依赖语音合成、表情驱动和自然语言处理自动生成内容与互动;混合驱动则是由 AI 和真人共同驱动,关键动作和内容由真人进行调整。
按技术实现方式分类:
- 2D 数字人:基于 Unity2D 和 Live2D 等技术实现
- 3D 数字人:基于 Unity3D、Unreal Engine 等游戏引擎实现
- 语音驱动型数字人:通过语音识别和合成技术驱动表情和肢体动作
- AI 生成型数字人:采用深度学习模型如 StyleGAN 和扩散模型生成数字形象和动作
按应用场景分类:
可分为信息助手型、泛娱乐型和企业级服务型,其中企业级服务数字人包括直播数字人、智能客服、虚拟主播、保险代理人、AI 数字员工、虚拟导游和讲解员等多种形式。
1.3 技术架构与核心能力
数字人的技术架构基于分层设计理念,涵盖从底层硬件支持到上层应用服务的完整技术栈。基础层为虚拟数字人提供必要的软硬件支持,硬件包含显示设备、光学器件、传感器和芯片等,而基础软件则包括建模软件和渲染引擎。
核心技术能力包括:
- 视觉感知能力:通过计算机视觉实现面部识别、表情分析和姿态估计等功能
- 语音交互能力:整合语音识别、合成和自然语言处理技术,提供语音驱动的互动体验
- 动作生成能力:通过动作捕捉技术或 AI 算法生成自然的面部表情和肢体动作
- 智能决策能力:基于深度学习模型和知识库实现智能对话和决策支持
- 实时渲染能力:支持高保真的实时渲染,以确保视觉效果的真实性
技术发展趋势:在 2024-2025 年间,数字人技术将在算法优化、硬件成本降低及应用场景拓展等领域实现重大进展。字节跳动开源的 LatentSync1.5 技术通过优化算法和训练数据集,显著提升了唇形同步的精度,同时减少了对高性能硬件的依赖,使数字人技术在消费级设备上能够流畅运行。京东科技通过语音合成的大模型 LiveTTS 和通用数字人大模型 LiveHuman,将单个数字人的生产成本从数万元压缩至两位数,相较于传统真人拍摄模式,成本下降幅度超过 90%。
二、数字人技术的实现方式与原理
1. 2D 数字人技术的实现
2D 数字人技术在实现上主要涵盖 Unity 2D 和 Live2D 两种主流技术路径。Unity 2D 是由 Unity Technologies 开发的跨平台游戏引擎,全球超过一半的游戏都是通过 Unity 创作的,因此在 2D 数字人制作中具有广泛应用。Live2D 则是专门为 2D 数字人制作而设计的专业软件,能以一张原画实现“2D 立体效果”。
Unity 2D 技术的实现原理:Unity 2D 利用传统的 2D 精灵动画技术,将人物形象拆分为多个独立部件,如头部、身体与四肢等,并通过骨骼动画系统来控制这些部件的运动与变形。Unity 2D 支持 2D 物理引擎、粒子系统和光照效果等高级特性,能够创建丰富视觉效果的 2D 数字人。
Live2D 技术的实现原理:Live2D 的核心在于将原画进行精细拆分,拆分越细,动部位越多,效果也越灵活。通过 Live2D 中的弯曲和旋转变形器实现动态效果,模型文件由纹理、骨骼和变形器等组件构成。Live2D 技术的优势在于能够以较低的资源消耗实现丰富的面部表情和肢体动作,特别适合二次元风格的数字人制作。
2D 数字人的渲染技术:2D 数字人的渲染主要使用传统的 2D 渲染管线,包括顶点着色器和片段着色器等核心组件。通过高质量的材质和纹理贴图来提升数字人的视觉效果,利用光照与阴影计算增强立体感和真实感。现代的 2D 数字人渲染技术还支持实时阴影、粒子效果和后期处理等高级特性。
2. 3D 数字人技术的实现
与 2D 数字人相比,3D 数字人技术在复杂程度和视觉效果上都有显著提升,主要依赖 Unity 3D、Unreal Engine 等专业游戏引擎进行开发。
3D 建模技术:制作 3D 数字人首先需要应用三维建模技术来创建人物的几何模型。主流的 3D 建模软件包括 Blender、Cinema 4D、3ds Max、Maya、Substance Painter 和 Modo 等。建模过程涵盖基础网格创建、细节雕刻、拓扑优化、UV 展开和纹理绘制等多个环节。
3D 骨架绑定与动画系统:为了将几何模型与虚拟骨架系统相连,3D 数字人采用了骨架绑定技术,并通过动画系统对骨架的运动和变形进行控制。当前的 3D 引擎已支持复杂的反向动力学(IK)系统、物理模拟以及动作捕捉数据的导入等多种高级功能。
- 实时渲染技术:3D 数字人的实时渲染是其技术实现的核心,主要包括以下几个方面:
- 渲染引擎架构:现代 3D 渲染引擎运用了基于物理的渲染(PBR)技术,结合实时光线追踪和可编程着色器,大幅提升了纹理细节和光影的真实感,渲染帧率可达到 60fps 以上。
- 材质与纹理系统:通过高品质的材质和纹理贴图,如基础颜色、法线贴图、粗糙度贴图及金属度贴图,实现了高度逼真的表面效果。
- 光照与阴影技术:借助实时光线追踪和路径追踪技术,采用智能采样策略(如自适应重要性采样)来提升渲染效率,降低计算冗余,同时在确保图像质量的基础上将渲染时间控制在毫秒级别。
- 性能优化技术:利用轻量化引擎,例如 OpenAvatarChat 的 LiteAvatar,能在 RTX3060 显卡上实现 4K 级别的 30FPS 实时渲染。其使用的高斯泼溅(Gaussian Splatting)技术比传统网格渲染快三倍,确保交互的流畅性。
虚幻引擎在 3D 数字人中的应用:虚幻引擎是 Epic Games 开发的跨平台游戏引擎,近年来在数字人制作领域得到了广泛的应用。借助虚幻引擎,开发者能够利用其强大的 3D 建模、动画、物理模拟和渲染功能,制作出高质量的数字人角色。虚幻引擎的 MetaHuman Creator 工具可以创建高保真的数字人,支持实时的面部和身体动画。
3. 语音驱动型数字人技术原理
语音驱动型数字人技术通过分析语音信号,实现数字人的面部表情和肢体动作的同步交互。其核心在于构建语音特征与面部动作之间的映射关系。
语音信号处理技术:
- 音频特征提取:将原始音频转化为梅尔频谱(MFCC)是基本步骤。系统对音频信号进行分帧处理,提取特征信息,例如梅尔频率倒谱系数(MFCC)和线性预测倒谱系数(LPCC)等。
- 音素分割与识别:准确的音素分割算法是后续嘴型驱动精确性的保障。音素(Phoneme)与视位(Viseme)并非一一对应,多个音素可能对应同一口型,因此音素 - 视位映射库的构建至关重要。
- 声学模型构建:声学模型用于将语音的声学特征与相应的音素相对应,语言模型则用于估计句子的可能性,以辅助识别结果的解码。
口型同步技术原理:
- 视位驱动方法:视位(Viseme)指的是与某一音位相对应的嘴、舌头、下颚等可视发音器官的状态。不同的发音对应不同的口型,通过建立音素到视位的映射关系,实现语音驱动的口型动画。
- 深度学习模型:构建深度网络模型(如 DNN、CNN、RNN 等),学习语音与口型 / 表情系数之间的映射关系。现代方法采用层次化的音频驱动视觉合成模块,将人脸细致划分为嘴唇、表情及姿态三个区域,分别学习这三者与音频的对齐关系。
- 实时驱动技术:NVIDIA 开源的 Audio2Face 模型能够深入分析音频中的音素,精准捕捉微小的肌肉运动,生成与任意语言高度匹配的口型。该技术还会分析音频的语调、节奏和音量,从中推测说话者的情感,以驱动一整套面部肌肉的联动。
多模态语音驱动技术:现代的语音驱动型数字人不仅能够实现口型同步,还能根据语音的情感、韵律等特征生成相应的面部表情和肢体动作。阿里达摩院推出的 EchoMimic V2 是一款基于语音驱动的肖像动画生成工具,不仅可以让虚拟人物实现口型同步,还能增加头部与身体动作,使 AI 形象更加生动。
4. AI 生成型数字人技术原理
AI 生成型数字人技术依托深度学习模型,自动生成数字人的形象、表情和动作,代表了数字人技术的最新发展趋势。
生成对抗网络(GAN)技术:
- GAN 基本原理:生成对抗网络由生成器(Generator)和判别器(Discriminator)构成,通过两者之间的对抗训练,生成器能够学习真实人像数据的分布,进而生成高质量的数字人像。
- StyleGAN 技术:StyleGAN 是 NVIDIA 于 2019 年提出的一种改进型生成对抗网络,在图像生成质量、训练稳定性和可控性方面取得了显著突破。StyleGAN2 的核心贡献在于 style-based 生成,将潜在向量(latent vector)映射到“风格向量”(style vector),以控制图像的不同层次(例如低层次控制颜色、纹理,高层次控制脸型、发型)。
- StyleGAN3 技术突破:StyleGAN3 通过改进的生成器架构与傅里叶特征输入,解决了纹理黏连问题。自适应实例归一化(AdaIN)层实现风格解耦,消除了噪声输入的频域约束,从而消除纹理震荡。实验结果显示,在 1024×1024 分辨率下,StyleGAN3 相比前代模型将特征解耦度提升了 37%。
神经辐射场(NeRF)技术:
- NeRF 基本原理:神经辐射场(NeRF)技术通过将场景表示为连续的体密度和颜色函数,从多角度图像中重建高保真的 3D 场景。在数字人制作中,NeRF 技术能够实现超写实数字人形象的生成与复刻。
- 动态 NeRF 技术:最新的动态 NeRF 技术可以处理动态场景,实现数字人的动作生成和表情变化。通过时空联合建模,能够生成具有时间连续性的数字人动画。
扩散模型技术:
- 扩散模型原理:扩散模型(Diffusion Models)通过在数据中逐步添加高斯噪声,然后学习去噪过程来生成新的数据样本。在数字人生成中,扩散模型能够通过噪声迭代生成逼真细节(如皱纹、发丝)。
- DiT 技术:DiT(基于 Transformer 架构的扩散模型)通过联合建模突破了分辨率与复杂场景的限制,使数字人具备实时交互、情感驱动和跨模态一致性。
多模态生成技术:
- 文本到数字人生成:通过文本描述生成相应的数字人形象,例如百度的文心一格、阿里的通义千问等大型模型都具备文本生成数字人的能力。
- 图像到数字人生成:基于单张或多张图像生成可动的数字人模型,如阿里通义开源发布的 LHM 可驱动的超写实 3D 数字人生成模型,能够在秒级内生成超写实的 3D 数字人。
- 视频驱动数字人:通过输入视频来驱动数字人的动作和表情,实现动作的迁移与表情的克隆。
5. 多模态驱动型数字人技术实现
多模态驱动型数字人技术整合了语音、视觉、手势等多种交互方式,使数字人能够以更自然、高效的方式与用户进行互动。该技术的核心在于多模态信息的融合处理与协同驱动。
多模态感知技术:
- 视觉感知:通过 RGB- D 摄像头(如 Intel RealSense D455)实现毫米级的动作捕捉与深度信息获取,结合面部识别技术实时捕捉用户的表情变化。
- 语音感知:借助骨传导麦克风(如索尼 EX3)实现高质量的语音采集,并结合语音识别技术理解用户的语音指令。
- 生理信号感知:通过生物传感器监测用户的心率、皮肤电反应等生理信号,结合情感计算技术分析用户的情绪状态。
多模态融合技术架构:
- 分层处理架构:基于多模态交互的虚拟人系统整合了视觉、听觉、触觉等多维数据通道,构建了分层处理架构。底层负责原始数据的采集与预处理,中层负责特征提取与模式识别,顶层则负责决策与响应生成。
- 情感计算模块:集成 OpenFace 与 iMotions SDK,通过微表情分析(眼睑运动频率、嘴角曲率)和语音韵律(基频波动、停顿间隔)构建情感向量,实现对用户情绪状态的精准识别。
- 多模态对齐技术:通过时间同步与特征对齐,确保不同模态信息的一致性。时钟同步算法是解决音画延迟的关键,通过精确的时间戳同步,将延迟控制在 50 毫秒以内。
实时交互技术:
- 智能决策系统:基于多模态输入分析,通过自然语言处理(NLP)技术解析文本情感,情绪强度影响动作幅度(如愤怒时动作急促)和语音合成参数(如悲伤时语速放缓)。
- 动作生成技术:基于语音中的情感、韵律及文本语义信息,快速匹配出相应的动作。虚拟人的所有表情都通过语义贯穿,实现动作与语义间的整体一致。借助动作表征抽取技术,能够迅速生成数字人的表情与动作,确保交互过程更加流畅。
- 跨模态生成技术:MIDAS 多模态交互式数字人合成技术通过对标准大型语言模型(LLM)进行最小化修改,接受包括音频、姿态和文本在内的多模态条件编码,并输出在空间和语义上连贯的表达,以指导扩散头去噪过程。
6. 技术对比与选择策略
不同类型的数字人技术在应用场景、技术复杂性和成本效益等方面存在显著差异,因此选择合适的技术方案时需要综合考虑多个因素。

技术选择策略建议:
- 成本为先的应用场景:在预算有限的情况下,推荐采用 2D 数字人技术或基于模板的 3D 数字人方案。京东科技通过技术创新,成功将单个数字人的生产费用从数万元大幅降低至两位数,从而为中小企业提供了更加经济实惠的选择。
- 效果为先的应用场景:对于需要高保真视觉效果的领域,比如虚拟偶像和影视制作,建议选择基于 UnrealEngine 的 3D 数字人技术或 AI 生成型数字人技术。
- 交互为先的应用场景:面对需要复杂交互功能的应用,比如智能客服和教育培训,推荐使用语音驱动型或多模态驱动型数字人技术。
- 技术发展趋势:随着人工智能技术的迅速进步,AI 生成型和多模态驱动型数字人有望成为未来的主流技术选择。预计到 2025 年,数字人将像水电一般深入人们的日常生活,极低的成本加上与真人不相上下的效果,极有可能使其成为企业探索和应用大模型的最佳切入点之一。
三、结论
回顾历史的变迁:
蒸汽机的出现使得纺织工人转型为机械师;
Photoshop 的问世则让修图师变身为视觉设计师;
那么,这一次数字人的到来,又将带来怎样的变革呢?
本文由 @AI Online 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来源于 Unsplash,基于 CC0 协议