共计 2528 个字符,预计需要花费 7 分钟才能阅读完成。
首先,小雷对于设计的了解几乎为零,毕竟这并不是我的职业领域。
然而,身处互联网的人,或多或少都会听说设计行业里那些传说中的难题,还有那些奇葩的客户要求。
常有人说,你的作品做得不错,那 大象能否转个身?这应该不成问题吧。
又有人说,你的黑色显得有些单一,能不能呈现一种 五彩斑斓的黑色 呢?

不论设计师们看到这样的要求会不会感到愤怒,作为一名从事文字工作的我,看到这些评论也感觉有些无奈。
更重要的是,你不能随意表达自己的意见,因为对面可是一位不懂这些的金主爸爸。
最终,无论客户的要求多么离谱,工作都得继续进行。即使是客户希望你把他照片中的拉链拉上,你所能做的就是截屏并分享到社交媒体上让大家开怀一笑,然后努力想办法解决问题以维持生计。

(图源:新浪微博)
然而,面对问题,总会有解决方案,只是这次的方案有些与众不同。
昨天,字节跳动的豆包大模型团队在其公众号上展示了最新的通用图像编辑模型SeedEdit。
官方称,这款模型的核心理念是「让一句话轻松 P 图成为现实」,用户只需输入简洁的自然语言,就可以对图像进行多种编辑,包括修图、换装、美化、风格转换,以及添加或删除指定区域的元素等。
听起来似乎有些不可思议?我也是这样想的。
让大象转个身
想要体验这个功能其实非常简单。
根据官方的介绍,目前该模型已经在 豆包 PC 端 和即梦网页端 进行测试,而豆包手机端暂时无法使用此功能。
接下来,只需点击侧边栏的「图片生成」,便能找到上传参考图的选项,这就是 SeedEdit 模型的入口。
操作非常简单,上传图片后,输入我们希望更改的内容。
例如,如果我想让画面中背对我们的大象转身,应该如何操作呢?
答案是,输入「让大象面对我」。

(图源:雷科技)
对比这两张图片后,我们可以看到,SeedEdit 生成的正面大象显得非常合理,其耳朵形状、四肢位置和身体颜色均表现得相当出色,周围环境也保持了高度的一致性,当然,细心的观察者仍可能发现部分石头的形状存在差异。

(图源:雷科技)
生成的图片 还能再次进行编辑,这一点实在令人欣喜。

(图源:雷科技)
然而,接下来的操作似乎变得不再顺利。
在豆包修改后的图片基础上,我继续提出了新的编辑请求,诸如 「让大象奔跑」、「让大象喷水」 和「让大象侧身」等,然而结果都不尽如人意。
例如,当我要求它喷水时,水确实喷了出来,但却是从象牙处喷出的,而非鼻子。
想要让大型模型掌握常识,确实是个挑战。

(图源:雷科技)
换个不同的人物,或者说是模型的相片来尝试一下。
由于家里的环境比较简陋,通常拍摄手办时背景都显得有些将就,没有时间和精力去精心布置场景。
不过现在,我让我尝试「将背景换成城市景观」。
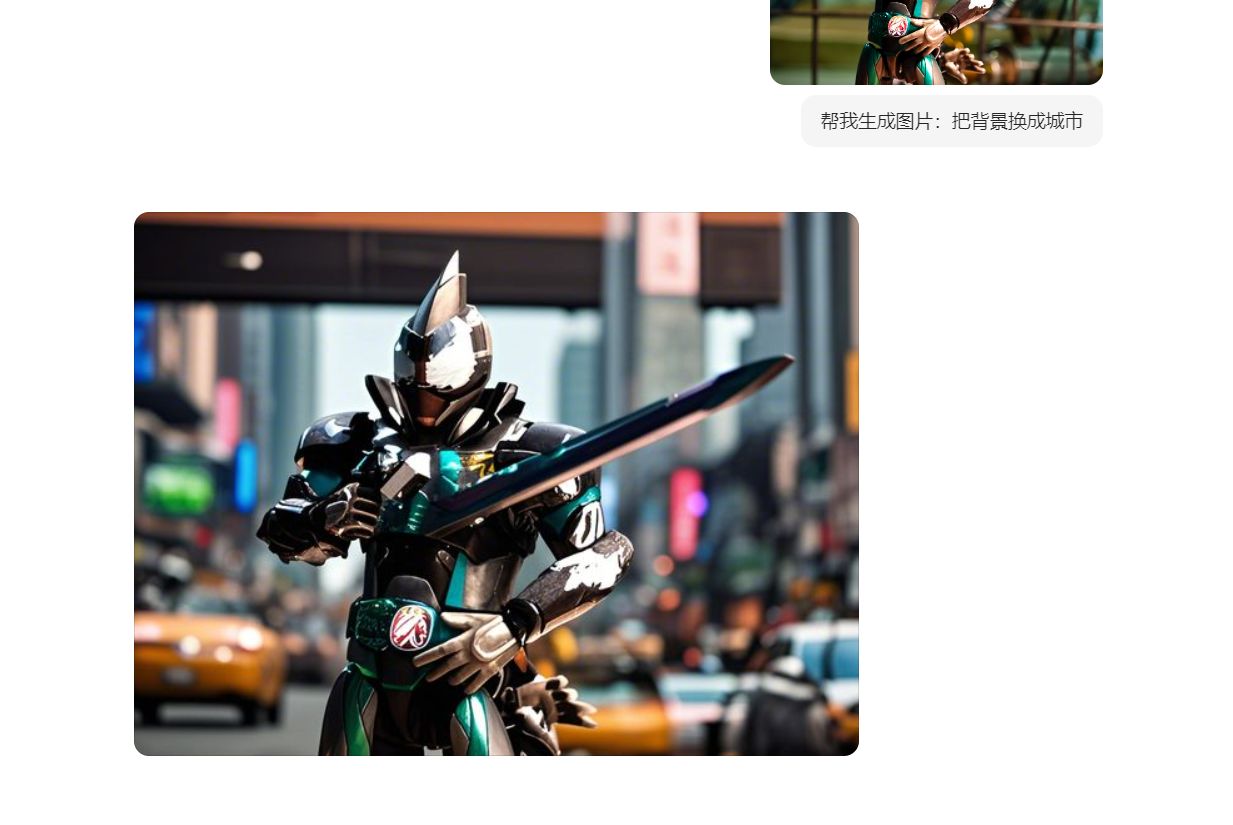
(图源:雷科技)
效果看起来有些平淡?那就尝试「夕阳下的光照效果」。
说实话,这一变化立刻让画面感增强,整个过程我仅仅给豆包下达了两条简单的指令,体验非常流畅。
对于资源有限的胶佬们来说,繁杂的布景和灯光调整的步骤或许真的可以省略。

(图源:雷科技)
当然,这些只是对原图的小调整,如果我希望直接更换画面的主体呢?
例如,想要「指鹿为马」。

(图源:雷科技)
实际生成的效果相当出色,不仅草地的背景得以完整保留,连马身上的细节纹理也被巧妙替换。
如果不对照原图,几乎很难察觉到比例上的不协调。
更换衣物也毫无障碍,连光影和褶皱的调整都非常到位。

(图片
我尝试了一下这款汽车模型,发现 SeedEdit 目前并未识别小米 SU7。
随后,我随意上传了一张五菱宏光 Mini EV 的图片,并输入了一个相当复杂的编辑指令。

(图片
最终生成的车型,虽然没法与玛莎拉蒂相提并论,但至少拥有了跑车的轮廓。
AI 修图的崭新时代
如今,AI 在艺术创作领域已经展现出了令人惊叹的潜力。
然而,在图像编辑方面,AI 技术依然相对滞后,精准修图的难题一直困扰着行业发展。
在今年之前,用户通常依赖 Stable Diffusion 的 ControlNet 插件 来满足这类需求。
该插件能够接收额外的输入图像,将其通过不同的预处理工具转化为控制图,从而作为 Stable Diffusion 扩散的附加条件,用户只需输入文本提示,即可在 保持图像主体特征 的情况下随意修改细节。
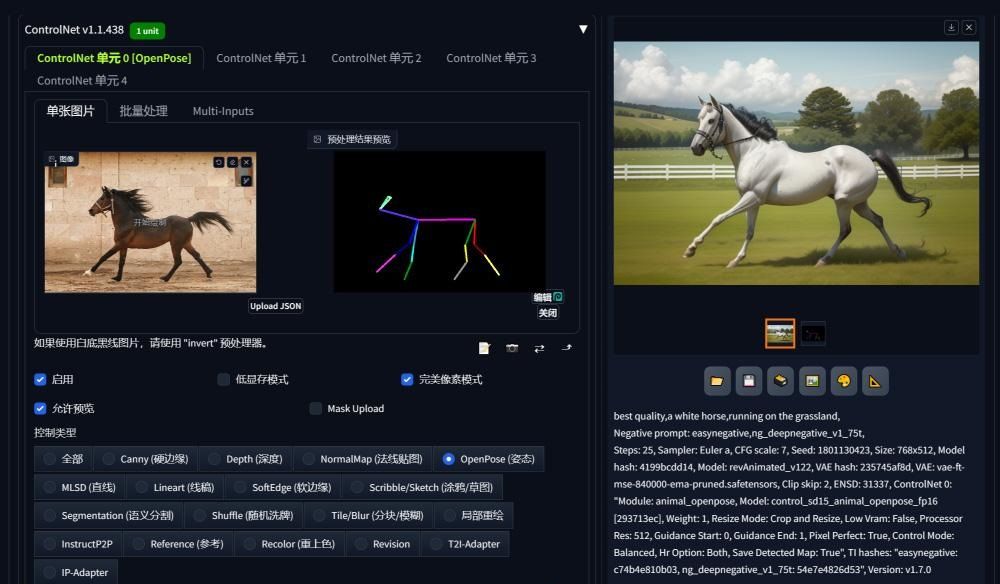
(图片
本地部署 AI 应用的过程,对于很多初学者而言几乎是不可及的。
因此,进入 2023 年后,ChatGPT/DALLE3、Midjourney 和百度超能画布等平台纷纷推出了局部重绘的功能,试图提供在线图片编辑的解决方案。
不过,这些应用在大多数情况下仍需要用户手动选择修改对象,并输入各种提示词进行编辑。
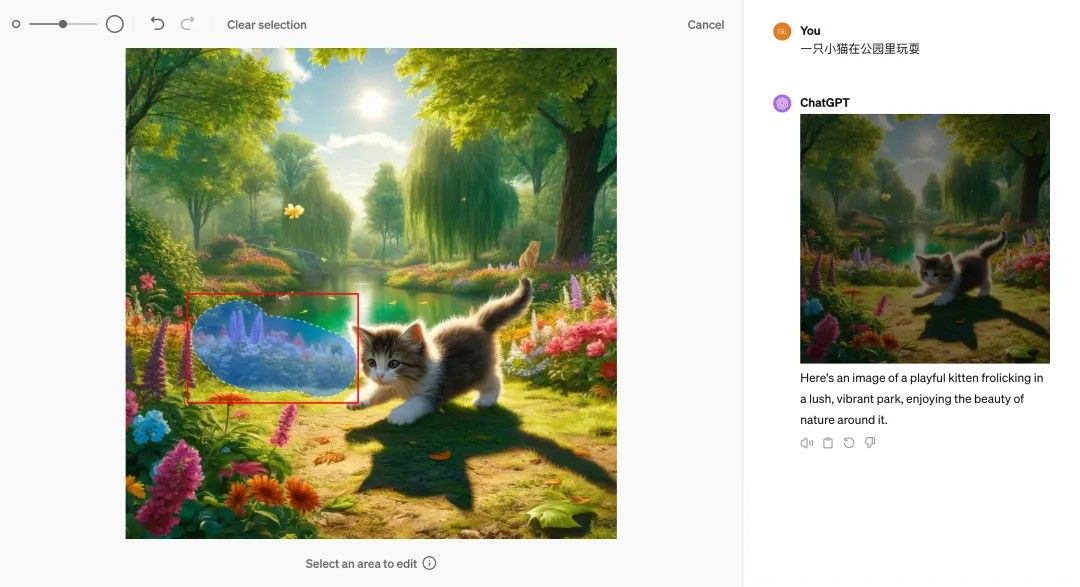
(图片来源:雷科技)
掌握正确的 AI 使用技巧是提升修图效果的关键,这在一定程度上提高了使用门槛。
假如,我们只需提供输入图片和简单的文本描述,模型就能够依据这些指令进行图像编辑,那将会是多么轻松的事情啊。
字节推出的 SeedEdit 确实在朝着这个目标努力。
然而,经过多次修图后,问题逐渐暴露出来,目前该模型在生成图像时仍存在一些缺陷。
首先,缺乏人像前后一致性。
一旦涉及到人的面部修图,最终生成的图像与原始图像的差异往往会显得十分夸张,几乎无法辨认出原本的样子。

(图源:雷科技)
其次,缺乏对图片内容的明确指导。
在涉及多个元素的图像中,SeedEdit 目前难以确定需要修改的具体部分。即使偶尔识别成功,生成的图片效果也可能显得极为扭曲。

(图源:雷科技)
最后,文字处理的能力仍显不足。
类似于早期的 AI 绘画,SeedEdit 当前也会生成一些虚构的文字内容。下面这三行看似有条理,但我费了好大劲,依然无法理解其真正含义。

(图源:雷科技)
在我看来,SeedEdit 的出现填补了国产大型模型在语义 AI 修图领域的空白。
可以预见,随着 AI 图像编辑技术的持续进步,未来的手机和电脑或许会普遍集成这类功能,类似于 AI 消除和 AI 放大,逐渐走入日常生活。无论是初学者还是专业人士,大家都将能够轻松上手,直观地表达自己对美的理解。
修图只需动手?这或许不再是幻想。