共计 2911 个字符,预计需要花费 8 分钟才能阅读完成。
豆包现已支持视频通话功能了!
自从年初推出「实时语音通话」功能以来,用户的热情持续高涨。如今,在社交平台上搜索豆包时,排名前十的热门词中,有六个与「打电话」相关。与豆包通话相关的创意内容也获得了观众的广泛关注。
随着视频通话功能的上线,豆包的通话体验实现了质的飞跃,变得更加实用和便捷。通过视频画面,即使是模糊的语音输入,AI 也能更好地理解,用户无需再费力组织语言来描述眼前的事物。
虽然视频通话看似简单,但其背后蕴含着语言处理、多模态理解、推理能力与知识库等多项技术的积累与整合,同时还实现了成本与效率的平衡。
更为重要的是,视频通话功能为 AI 助手的未来发展提供了新的可能。当 AI 拥有了视觉和听觉的能力,结合未来更多的硬件创新,将释放出更大的创新潜力。
01
豆包——帮你解读眼前的一切
视频通话能力的引入,使豆包在多模态理解和交互体验上得到了显著提升。
从最基础的「理解」场景开始,用户可以将手机摄像头对准任何信息,如信息板或菜单,从而让豆包进行翻译或解释。在此过程中,用户可以通过语言输入不断调整豆包的关注重点。
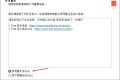
例如,在博物馆内,当我们开启视频通话询问豆包这是什么时,豆包会根据画面中的地标特征识别出这是「新加坡国家美术馆」。如果我们继续询问楼上的横幅含义,豆包则能提供具体展览信息的翻译与解释。
在展览过程中,我们也可以举起手机,随时向豆包提问关于任何一幅作品。从基本的作品信息翻译,到询问作品的风格归属和是否模仿了某位艺术家,豆包都能提供精准的判断。
基于豆包提供的信息,我们还可进一步探索更深层的关联。例如,在新加坡国家美术馆中,有一个法院拘留室的展示区域。当我向豆包询问后,发现这个区域与新加坡国家美术馆由原政府大厦和原最高法院大楼改建有关。曾用于拘留候审被告的拘留室,在改建后被保留,成为美术馆的一部分,供公众参观,使人们了解新加坡的司法历史。

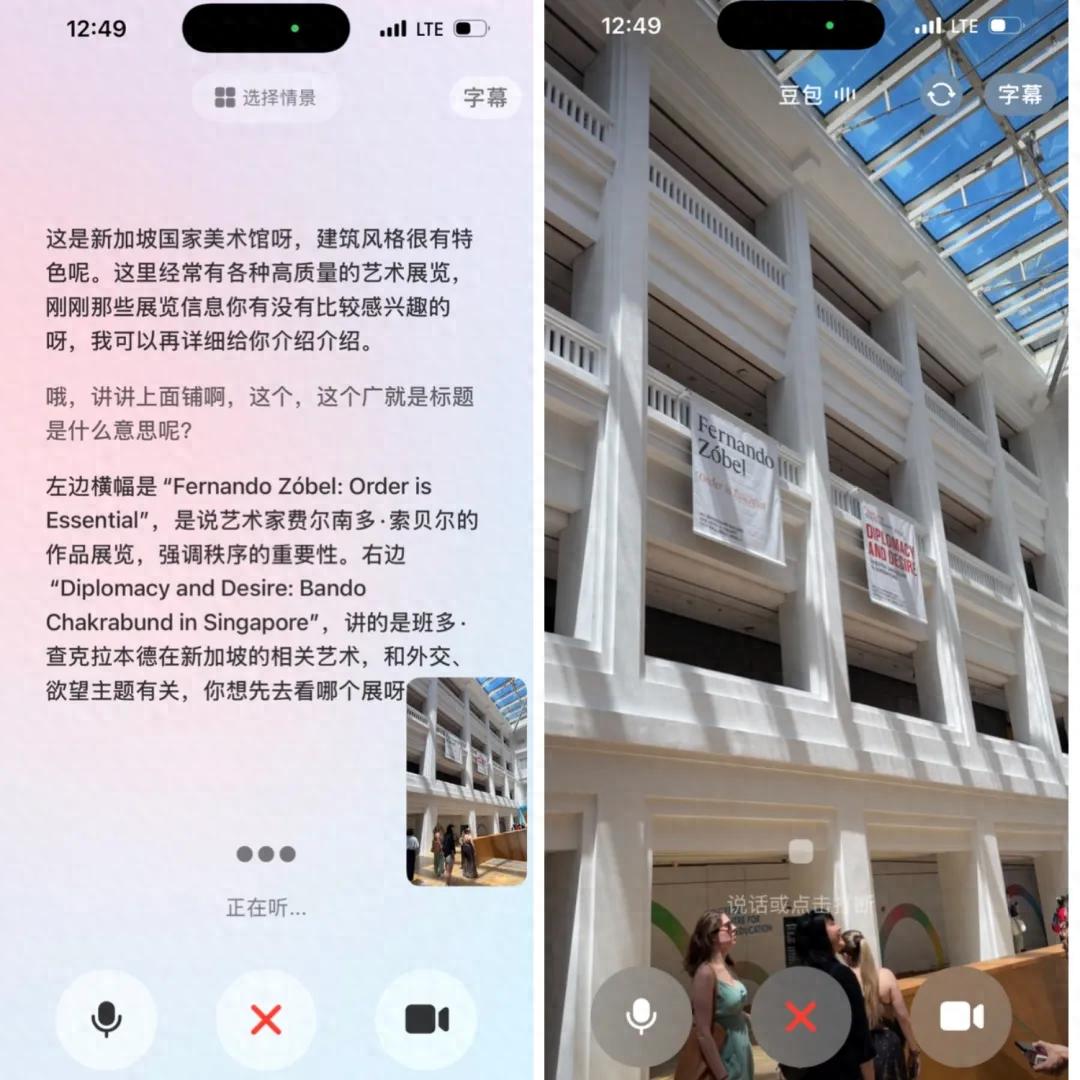
此外,我们还可以与豆包分享自己对美术作品的理解与见解,进行观点的碰撞。实际上,豆包已具备一定的「纠错」能力,不会只是迎合用户的理解。例如,当我错误地将某个作品类比为「蒙德里安」风格时,豆包能够及时纠正我,指出实际更像安迪·沃霍尔。随后我们还可以深入探讨,探讨为何会产生这个错误。我们也可以引导豆包进行批判性分析和评价。
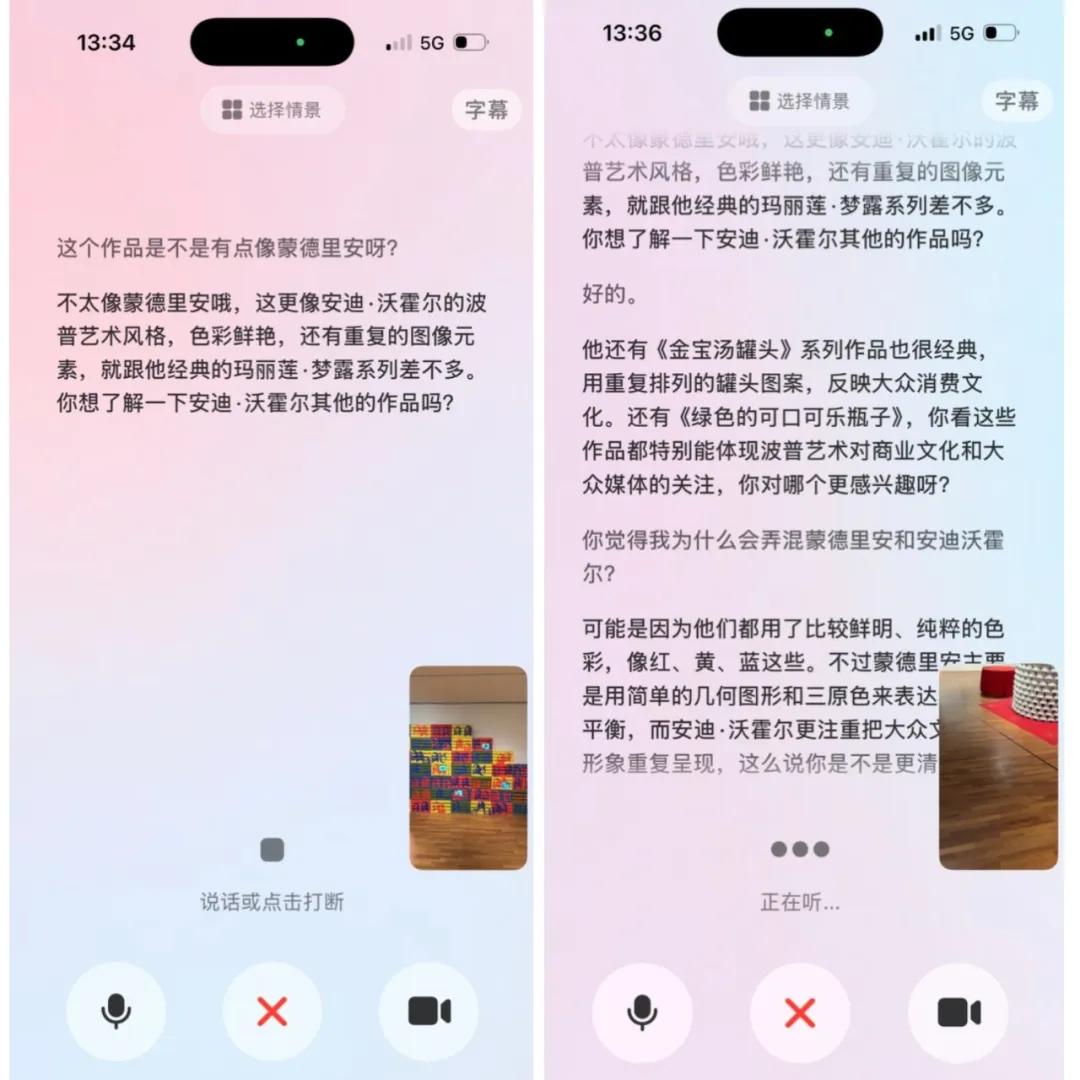
一个重要的因素是,借助图像信息作为辅助,即便我发出的指令声音较小,豆包未必能完整识别我所说的每一个字,但它依然能通过捕捉关键词,准确理解我的意图。
在旅行、观光、展览等场景中,豆包的视频通话能力展现出显著优势。我们可以随手举起手机,让豆包看到我们眼前的事物,从最简单的「这是什么?」开始,逐步挖掘更多的信息和知识。例如,让豆包根据周围的景色推测我们的所在位置,并推荐周边值得游玩的景点、活动和特色美食,这不仅实用且充满乐趣,非常适合那些喜欢偶然惊喜的出游者。

在餐厅用餐时,遇到「不知道该怎么吃」的情况,也非常适合通过视频通话功能向豆包求助。比如,吃荞麦面时,服务员端上来一壶像热水的东西,这时豆包轻松告知,那壶里装的是荞麦面汤,可以与酱汁混合后饮用。

豆包的视频通话功能,相较于传统的图像识别,其关键优势在于更强的「互动性」。依赖单张图像的理解与推理,常常会产生各种偏差与错误。而借助视频模式,即使豆包给出的回答存在疑点,我们也能通过换个角度,提供更多信息,给予豆包更多思考与纠正的机会。
例如,在询问酒店某个装置的功能时,豆包最初误认为我问的是熨衣板。经过进一步的交流,它意识到我想询问的是行李架,但由于视角问题,它错误地将行李架理解成了健身器材。之后,我调整角度再询问,豆包最终成功识别出是行李架。

这正是视频通话功能的关键优势。当前,任何 AI 大模型都无法避免出现「幻觉」或错误。当用户精心编写的提示没有得到理想的输出时,往往会打击他们使用 AI 的积极性。然而,通过提供更多信息和不同角度的输入,可以让 AI 更接近我们希望得到的正确答案。可见,在视频通话场景中,AI 与用户之间形成了一种积极的互动循环。
除了日常场景,豆包的视频通话功能在学习、工作等方面也能发挥巨大作用,尤其是在基于纸质材料进行理解和修改时。例如,对多页纸质资料进行总结,或对学科问题进行解答与纠错。
02
模型技术的「木桶理论」
尽管「视频通话」功能本身非常简单,任何用户都能轻松理解,但其背后却依赖复杂的技术支持。
豆包视频通话功能的核心来源于「豆包视觉理解模型」。2024 年 12 月,豆包首次发布该视觉理解模型,为视频通话功能奠定了基础。
除了视觉感知,豆包视觉理解模型还具备深度思考的能力。这使得豆包能够通过摄像头直接解答学科问题、分析论文和调试代码等任务。因此,在视频通话过程中,豆包能够结合「图像画面」和「用户语音指令」,精准理解用户的意图。
豆包并非是首个实现此功能的 AI 助手,但同时具备优秀的视觉理解能力,并能在视觉理解与用户指令之间综合信息生成用户想要的结果,同时保持低延迟,这一切都具有极高的技术门槛。
这整个过程有点像「木桶理论」,一个模型必须在多个方面都表现出色,才能像真正的「AI 助手」一样满足用户需求。
03
为什么「视频通话」能激发 AI 交互的更多创新?
如今,「视频通话」只是豆包的一个小功能,但实际上,视觉理解能力蕴含的潜力和可能性远不止于此。
自诞生以来,大模型 AI 助手的交互方式主要是「一问一答」,用户输入提示,AI 生成反馈。这里最大的矛盾在于,编写提示存在门槛,而这一门槛往往比预想的更高,而「一问一答」的交互方式也容易导致沟通的断裂,用户与 AI 之间也会感到距离。
而视觉图像的引入,为人机交互提供了一个「语境」,更重要的是,这种语境的建立不需要任何门槛,天然富含信息,用户只需举起摄像头即可。实际上,人类理解世界的过程中,最重要的信息接收器官始终是眼睛。
通过豆包的视频通话功能,这一模式的有效性已经得到了验证。借助连贯的互动和视觉理解,用户与 AI 的交互过程变得更加自然,用户可以通过不断补充和解释,逐步接近自己想要的结果。这种用户与 AI 之间的相互引导,能显著提高提示输入的宽度和准确性。
实际上,这早已成为行业共识。自 AI 大模型技术问世以来,几乎所有硬件创新都在探索一种「摄像头 + 麦克风」的组合。从 AI Pin 到各种 AI 智能眼镜,都是在建立一种让 AI「看 + 听」的感知模式。不过,目前大多数这类硬件在性能和效率上尚未达到手机的高可行性。
当我们使用豆包的视频通话功能时,依然能感受到它受到手机硬件的限制。例如,很难长时间将手机对准前方的物体,且在公共场合也不便大声说话,无法与 AI 充分进行语音交流,这些都是智能手机作为传统硬件的局限。
从豆包的「视频通话功能」中可以看出,让 AI「看 + 听」的输入模式,可能代表着 AI 交互的更多可能性。这在软件上完全可行,随着模型能力的不断发展,加上硬件创新,或许将进一步改变我们与 AI 的互动方式。