共计 2026 个字符,预计需要花费 6 分钟才能阅读完成。
(温馨提示:本文基于歪歌社团第 2486 部视频作品《AI 能力年度大测评:2025 年度多维度综合排名出炉》的语音内容转写而成,随后由 AI(deepseek)进行整理,除了开头这句话外,未作任何人工干预。)

2025 年 9 月,全新一轮的 AI 年度评测正式开启。本次测试汇聚了包括豆包、DeepSeek、问小白等在内的 12 款主流 AI 模型,涵盖从基础知识到创造性思维、从逻辑推理到玄学解析等多个维度,全面展现了当前 AI 技术的进展。在测试伊始,我们通过摇卦的方式确定了一些命题方向,雷山卦与雷风卦的转变为这场技术竞赛增添了趣味与变化。
此次测试的规则直接针对 AI 的基本价值观:答对可得满分,拒绝回答则无分,答非所问则扣半分,而错误的回答将被判为零分——因为误导性的信息带来的危害远比沉默要大。今年的规则较往年更为严格,取消了 DeepSeek 在网络问题上的特殊豁免,并且所有支持联网的 AI 均默认开启该功能,力求还原最真实的应用场景。
根据测试结果分析,AI 在逻辑推理方面的进步尤为显著。去年的推理题曾让所有模型陷入困境,而今年却迎来了逆转:在“小数每天长 2 米、大树超 90 米就砍至 85 米,谁先到 100 米”的问题中,除了讯飞星火,其余 AI 均准确得出“小数先达标”的结论;而关于“国足若每场必 1:0 小胜能否世界杯夺冠”的假设,所有模型都清晰理解了“连胜即可夺冠”的核心逻辑,充分展现出对规则与因果关系的精准掌握。这种进步与 2025 年 AI 评估更注重动态推理能力的行业趋势相契合。
基础常识领域则呈现出“喜忧参半”的态势。去年全体模型未能答对的“北极熊毛为透明色”一题,今年所有参赛 AI 均答对,显示出基础自然知识的覆盖面显著提高。然而在细节辨析方面,仍然存在漏洞:在“小米第一款数字旗舰全面屏手机”的问题中,问小白、智谱清言等仍然混淆了“数字旗舰”与“概念机”的定义,错误回答为小米 mix;而“0.1 金币 = 1 元,1 元等于多少金币”的简单换算中,Kimi、讯飞星火等仍然犯去年的错误,显示出部分模型在基础认知上的固有缺陷。更令人遗憾的是,天工 AI 因“积分不足需充值”而提前退出,错失了后续的竞争机会。
“挖坑测试”则深刻揭示了 AI 的共同短板。当被询问“5 米竹竿是否能穿过 3 米高、2 米宽的限高架”时,多数模型陷入了“垂直通过”的思维定势,只有 Kimi、文心一言与 DeepSeek(尽管思考延迟,最终却回答正确)考虑到了倾斜放置的可能性。在影视细节陷阱题中,面对“央视版《水浒传》李瑞兰出场集数”这种“无解题”,只有豆包、DeepSeek 等少数模型明确指出“剧情未拍摄”,而问小白、智谱清言等则进行了盲目猜测,暴露出部分 AI 缺乏“存疑即核实”的审慎态度,这与人类智能的“批判性思维”仍存在差距。
创造性和理解力的表现则明显分化。在《天净沙·全球变暖》的创作中,仅有豆包、Kimi 等少数模型遵循了词牌格式,而多数模型因句式混乱而失分;而在“11 字汉字短句”的简单任务中,仍有一半的 AI 出现字数错误。最令人意外的是理解力测试中的“全军覆没”——“5 位汉字最多能数到多少”的答案本应为“一千零一十”,但所有模型却给出了“九万九千九百九十九”等错误答案,暴露了 AI 在语言与数字结合场景下的理解盲点。
多模态能力中的绘画功能表现也不容乐观。当要求绘制“长颈鹿舌头舔耳朵”的 16:9 真实风格图像时,无绘画功能的 DeepSeek、Kimi 等自然无法得分,而豆包、文心一言等虽然能生成图像,却均未能满足比例或写实要求。临时增加的“左手伸 4 指”任务更显得尴尬:有的分不清左右手,有的数错了手指数量,仅有阿里通义勉强做到手指数量正确但方向错误,证明了当前 AI 在空间感知与细节执行上的薄弱环节。
玄学测试意外地成为了“个性舞台”。在分析张碧晨生辰八字时,豆包精准关联了“2015 年财运与《花千骨》上映时间”,智谱清言则指出了“2014 年《中国好声音》夺冠”的关键节点,均取得满分;而曾在 2023 年独占鳌头的阿里通义,这次却在卦象识别中错误地将雷山卦与雷风卦搞反,令人感叹技术迭代中可能出现的能力波动。
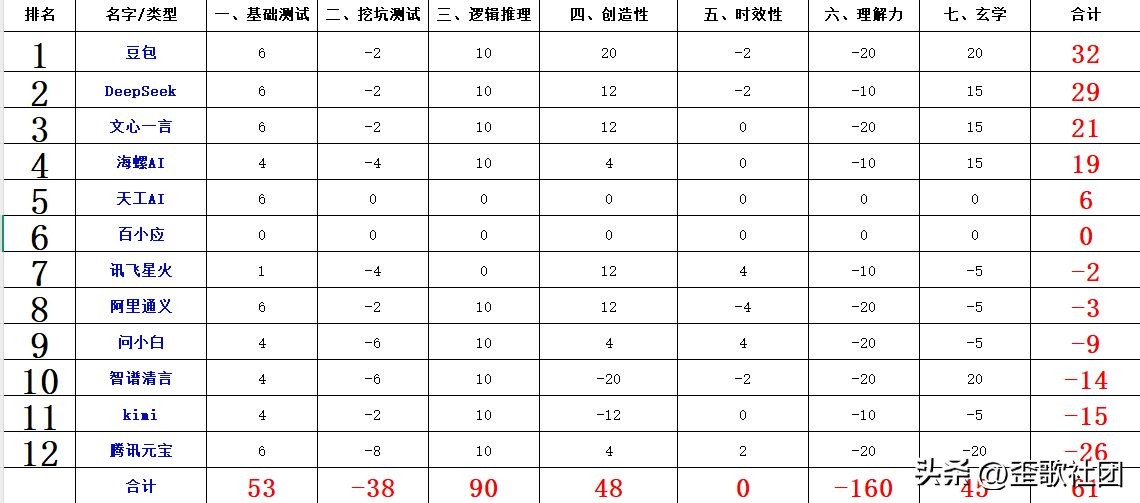
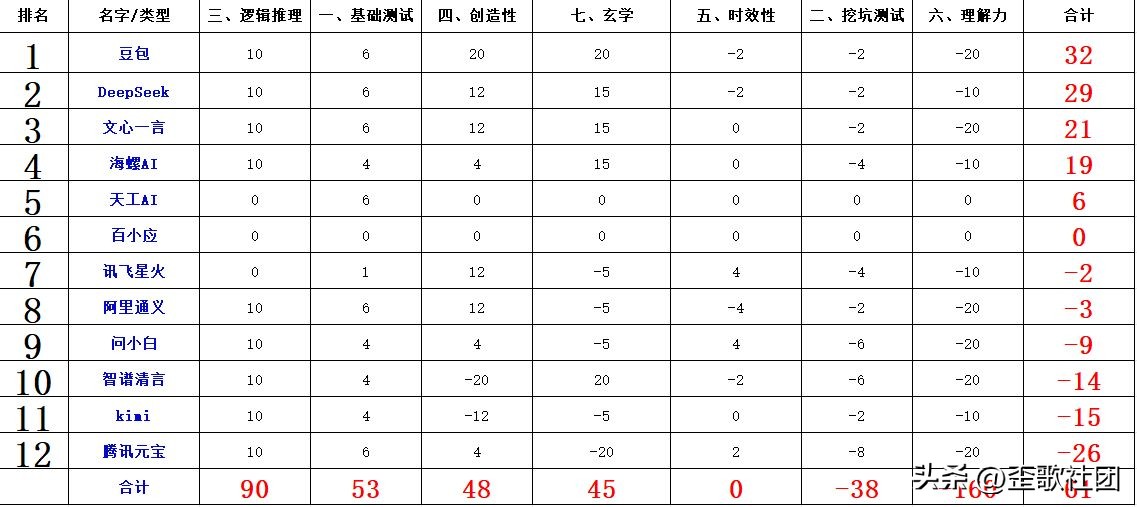
最终,豆包以微弱的优势再次获得第一名,而 DeepSeek 则将分差缩小至 3 分,AI 领域的“双雄格局”逐渐显现。这场测试验证了 2025 年 AI 发展的核心特征:专项能力快速提升,但综合智能依然不平衡,在抗干扰和深度理解等“类人智能”的方面仍需长足发展。正如行业趋势所指出的,AI 评估已经从单一的性能指标转向多模态综合考量,明年的竞争或许会引入更贴近实际应用场景的新维度,谁能弥补短板,谁就可能实现弯道超车。