共计 2990 个字符,预计需要花费 8 分钟才能阅读完成。
编辑:机器之心团队
数字人随着声音的变化而调整口型,这已不再是新奇的技术了。然而,更令人兴奋的是,当轻快的旋律响起时,数字人不仅会微笑,眼神中流露出的情感也随之而来;进入说唱部分时,它将伴随着节拍轻轻摇摆,手臂和肩膀有节奏感地带动整个氛围。观众所看到的,不仅是嘴唇的动作,而是一个完整的表演。这种表现方式超越了短暂的片段,能够在长达数分钟的视频中保持动作的自然流畅性。
最近,快手可灵团队将这一设想付诸实践。全新数字人功能现已在可灵平台上开启公测,并逐步向更多用户开放。相关的技术报告 Kling-Avatar 和项目主页也已同步发布。该报告详细解析了支撑可灵数字人技术的路径,明确了如何将一个仅能跟随声音对口型的模型,转变为能够根据用户意图进行生动表现的解决方案。
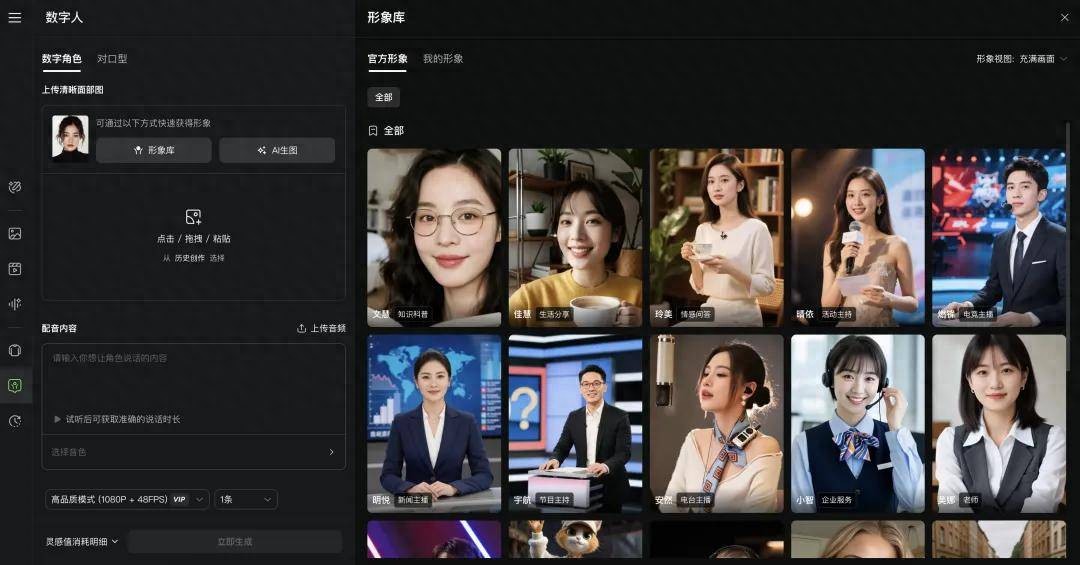
可灵数字人产品界面。访问地址:https://app.klingai.com/cn/ai-human/image/new


- 相关论文链接:https://arxiv.org/abs/2509.09595
- 项目主页地址:https://klingavatar.github.io/
接下来,让我们来看看一些实际效果:



文中视频链接:
https://mp.weixin.qq.com/s/IaFZy46DxSzcy2q2l10ojA
这些卓越效果的实现,得益于快手可灵团队精心构建的一套基于多模态大语言模型的两阶段生成框架。
多模态理解,令指令转化为可执行的故事脉络
Kling-Avatar 利用多模态大语言模型的生成与理解能力,设计了一个多模态导演模块(MLLM Director),将三种输入整合成一条清晰的叙事线索:从音频中提取语音内容及情感变化;从图像中识别人脸特征和场景元素;结合用户的文字提示,融入动作风格、镜头语言和情感变化等元素。导演模块输出的结构化剧情描述,再通过文本跨注意力层注入视频扩散模型中,生成一段全局一致的蓝图视频,明确了整个内容的节奏、风格和关键表达节点。
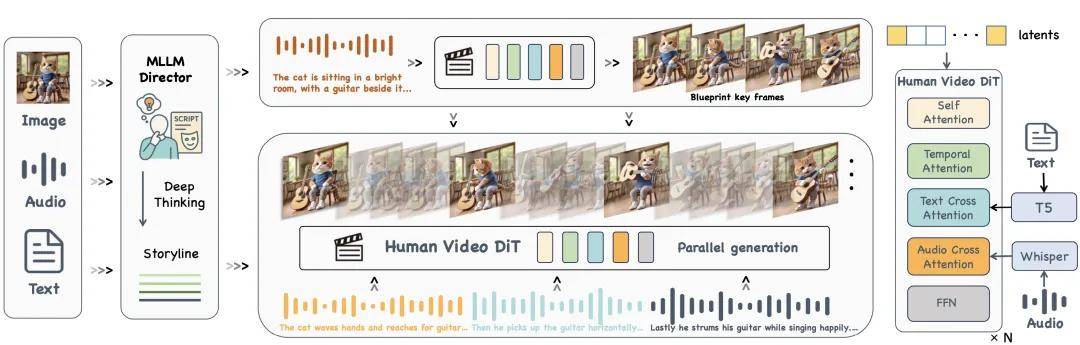
Kling-Avatar 的框架设计。多模态大语言模型(MLLMs)赋能的 MLLM Director 首先将多模态指令解读为全球语义和连贯的故事线,基于此生成一个蓝图视频,并从中提取首尾帧作为条件控制,进而并行生成子段视频。
两阶段级联生成长视频的框架
蓝图视频生成后,系统会依据身份一致性、动作多样性、避免遮挡及表情清晰度等条件,自动选择若干高质量关键帧。每对相邻的帧将作为 首尾帧条件 ,用于生成一个子段落。所有子段落根据相应的首尾帧并行合成,最终拼接成完整视频。为避免首尾帧与实际音频节拍的错位,方法还引入了 音频对齐插帧策略,确保口型与声学节奏在帧级别上保持同步。
此外,团队还精心制定了一系列训练和推理策略,以确保视频生成过程中音频与口型之间的对齐与身份一致性:
- 口型对齐:将音频切分为与帧片段对齐的小段,通过滑窗方式注入音频特征;自动检测嘴部区域并加权去噪损失;手动扩展视频帧,以增强在远景场景下人脸占比较小情况下的对齐效果。
- 文本可控性:冻结文本跨注意力层的参数,避免基座视频生成模型在特定数据上过拟合,从而削弱文本控制的效果。
- 身份一致性:在推理阶段针对参考图像构建“退化负样本”,作为负向 CFG,以抑制纹理拉花、饱和度漂移等身份漂移现象。
训练与评估数据流程
为了获取多样且高质量的训练数据,团队从演讲、对话、歌唱等高质量语料库中收集了数千小时的视频,并训练多种专家模型,从多个维度评估数据的可靠性,例如 嘴部清晰度、镜头切换、音画同步和美学质量。经过专家模型筛选出的视频,随后进行人工复核,最终形成数百小时的高质量训练数据集。
为了验证方法的有效性,团队构建了一个包含 375 个“参考图–音频–文本提示”的评估基准,涵盖了丰富的输入样例,包括真实人与 AI 生成图像、不同种族,以及开放情境中的非真实数据;音频涉及中文、英文、日文、韩文等多种语言,包含不同语速和情感的台词;文本提示则展示了多种镜头、人物动作和情感表达控制。该评估基准为现有方法提供了极具挑战性的测试情境,能够全面评估数字人像视频生成技术在多模态指令跟随方面的能力,并将在未来开源。
实验结果的对比分析
在定量验证方面,团队设计了一套基于用户偏好的 GSB(Good/Same/Bad) 评估体系。每个样本由三位评测者逐一比较 Kling-Avatar 与对比方法,并给予“更好”(G),“一样”(S),“更差”(B)的评分。最终报告 (G+S)/(B+S) 作为指标,衡量“更好或不差”的比例。同时在四个维度提供详细结果:整体效果、口型同步、画面质量、指令响应及身份一致性。对比方法选择的是最先进的 OmniHuman-1、HeyGen 等产品。
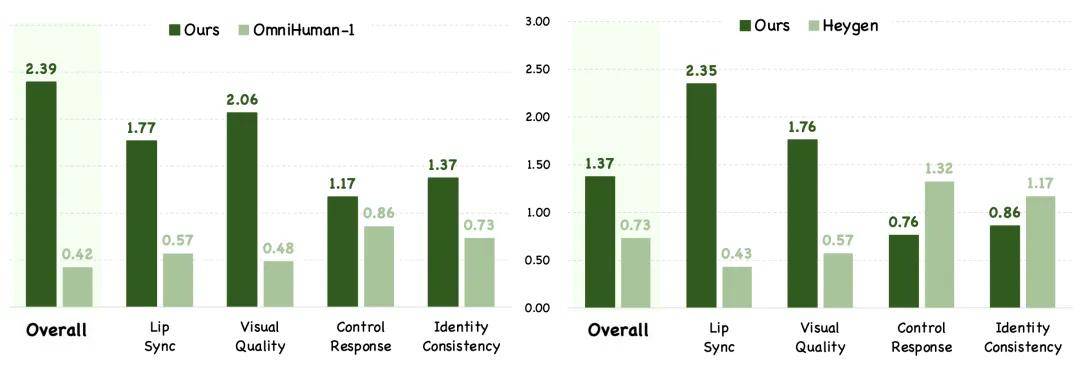
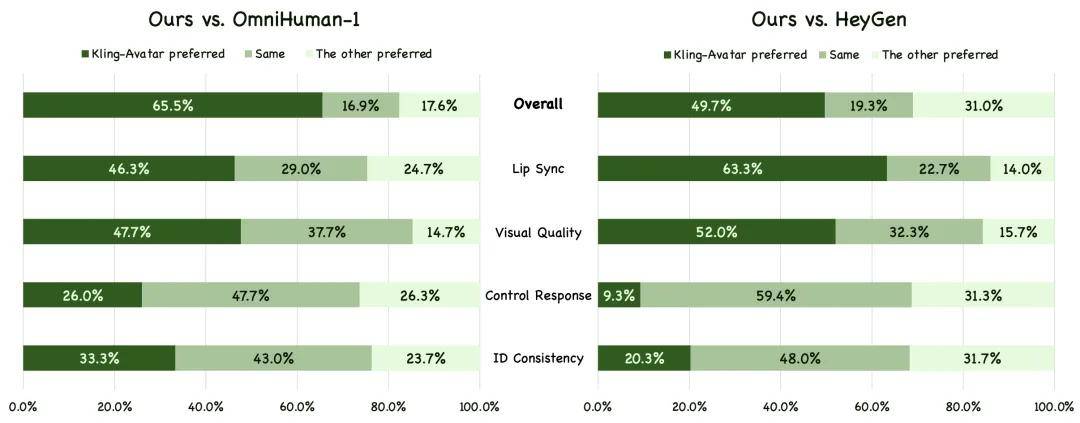
基于测评基准,与 OmniHuman-1 和 HeyGen 的 GSB 进行了可视化比较。结果显示,Kling-Avatar 在大多数维度上都表现优异。
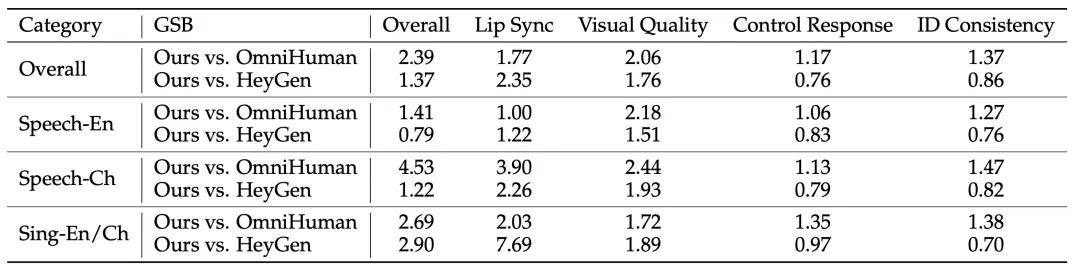
在所有基准和各个子测评集的 GSB 指标中,Kling-Avatar 整体超越了 OmniHuman-1,并在大部分指标上击败了 HeyGen。
通过多种场景的对比测试,Kling-Avatar 所生成的唇形不仅在时序和形态上与音频高度一致,还能使面部表情随语音的变化而展现出更自然的状态。即使面对发音难度较大的音节(例如“truth”,其标准发音为 [truːθ],[u:] 的发音要求双唇前突、口型小而紧)或高频语音中的短暂静音段,Kling-Avatar 也能准确再现相应的口型状态。

在情绪、动作和镜头三类控制方面,Kling-Avatar 能够更加精准地体现文本中的意图。在歌唱、演讲等复杂场景中,其动作与镜头的调度更加符合语义。下面的图表展示了 Kling-Avatar 生成的一些视频示例,展示了诸如“兴奋”的情绪控制和“镜头缓慢上移”的镜头控制,生成效果均令人满意。

Kling-Avatar 另一个显著优势在于其长视频生成能力。它采用了两阶段生成与级联并行生成的框架,使得在获得蓝图视频后,可以从中选取任意数量的首尾帧,进行并行生成每个子段视频,最终将这些段落完整拼接起来。这种方法使得总生成时间理论上与生成单段视频相当,因此可以快速且稳定地生成长视频。下面的例子展示了生成一段时长为 1 分钟的视频,生成结果在动态性、身份一致性及口型等方面均表现优异。

结论
快手可灵团队开辟数字人演绎新天地
快手可灵团队从“机械对口型”升级到“生动表演”,成功探索出一种全新的数字人生成模式。这一创新使得在几分钟的长视频中,数字人能够展现出细腻的情感、丰富的表现力和统一的角色形象。现如今,Kling-Avatar 已经融入可灵平台,欢迎大家前往体验新版数字人应用,感受你的声音与思想如何通过一镜到底的方式被生动演绎。
近年来,快手可灵团队不断深入研究多模态指令控制与理解,致力于数字人视频生成的解决方案。除了 Kling-Avatar,团队近期还推出了实时多模态交互控制的数字人生成框架 MIDAS,这两项技术在“表达深度”和“反应速度”上均取得了显著进展。展望未来,团队将继续在高分辨率、精细动作控制和复杂多轮指令理解等领域进行深入探索,力求让每一次数字人的表达,散发出真实而动人的灵魂。

利用AI智能写作工具,轻松生成高质量内容。无论是文章、博客还是创意写作,我们的免费 AI 助手都能帮助你提升写作效率,激发灵感。来智语AI体验 ChatGPT中文版,开启你的智能写作之旅!