共计 12294 个字符,预计需要花费 31 分钟才能阅读完成。
由哥伦比亚大学的刘禾教授所著《弗洛伊德机器人:数字时代的哲学批判》,最初于 2010 年以英文出版,今年推出了其中文版。
刘禾教授强调,《弗洛伊德机器人》的研究核心在于数字技术对现代文明的深远影响。书中,她引入了“控制论无意识”这一关键概念。数十年来,关于机器是否能够实现认知和具备与人类相同智力的讨论,往往集中在机器是否拥有意识上。然而,这一问题本身暗含了一个重要的假设:即将意识视为智能的唯一标准,并假设以自我意识为中心的“人”作为参照。这一视角的根本缺陷在于完全忽视了无意识在人的行为中的作用。刘禾教授运用拉康的精神分析理论,探讨了机器的运作逻辑与人类无意识结构之间的相似性。
那么,为什么人工智能可以被视为人类无意识的产物呢?今天,活字君将与书友们分享澎湃新闻资深记者丁雄飞对刘禾教授的专访,深入了解她近年关于人工智能的哲学基础的思考。

刘禾谈人工智能:
是谁将哲学引入计算机领域?
采访︱丁雄飞
本文摘自“上海书评”

刘禾,拥有哈佛大学比较文学博士学位,曾在伯克利加州大学和密歇根大学任教,现担任哥伦比亚大学东亚系及比较文学与社会研究所的终身人文讲席教授,曾担任该研究所所长,并荣获古根汉奖。她的著作包括《跨语际实践:文学、民族文化与被译介的现代性(中国,1900-1937)》《帝国的话语政治:从近代中西冲突看现代世界秩序的形成》《弗洛伊德机器人:数字时代的哲学批判》《剑桥的陌生人》,并编著了多部作品。
人工智能的技术进步为何与哲学的探讨息息相关?
丁雄飞: 您于 2021 年和 2023 年在《批评探索》(Critical Inquiry)上发表了两篇长文,分别是《机器中的维特根斯坦》(Wittgenstein in the Machine)和《图灵之后:哲学如何走进人工智能实验室》(After Turing: How Philosophy Migrated to the AI Lab)。您在文中清晰地区分了“人工智能实验室中的哲学实践”与“人工智能哲学”,前者涉及在机器内进行的哲学探索,而后者则聚焦于人工智能的哲学思考。能否请您总体谈谈人工智能与哲学之间的关系?尤其是针对您研究的剑桥语言研究小组,您为何认为其工作“首先是一场哲学突破,其次才是一项技术创新”?
刘禾: 我撰写这两篇文章,确实是想深入探讨哲学与人工智能之间的联系。目前围绕人工智能的讨论,无论在专业领域还是媒体和公众层面,哲学似乎并未得到应有的重视。人们的关注通常集中在技术的潜能及其可能带来的改变,甚至有论者重提人工智能可能会威胁人类生存的观点。
然而,这类言论早在几十年前就已出现,只是随着计算机和大数据技术的迅速发展,人工智能的角色及其社会关注度变得空前显著,导致人们更倾向于专注于技术本身。
追溯到上世纪五十年代,自图灵测试提出以来,哲学问题一直是推动人工智能研究的关键动力。正如“人工智能”这一术语的创始人约翰·麦卡锡所指出的,人工智能与哲学息息相关,因为其直接涉及认知问题:若要设计出能模仿人类行为的机器,首先必须对“认知如何发生”这一问题进行哲学层面的探讨。
我曾研究剑桥大学的语言研究小组。该小组由维特根斯坦的学生玛格丽特·马斯特曼于 1956 年创立。她邀请了一批数学家和对计算机研究感兴趣的学者,尝试在当时仍较为原始的计算机上进行信息检索和机器翻译实验。
在冷战初期,机器翻译被视为一项战略任务。美国急需将大量苏联情报翻译成英文,但懂俄语的人才极为稀缺。于是,美国国家科学基金会、海军、空军均投入巨资,希望在机器翻译领域取得突破。然而,研究人员很快发现,机器翻译面临着诸多挑战:究竟应该在词与词之间,还是句子与句子之间建立对应关系?句法又该如何处理?这些问题都成为难题。乔姆斯基的转换生成语法理论正是在回应这些问题的背景下产生的。
最难以解决的一个问题是词的多义性,或是词与概念之间的纠葛。传统人文学者往往将词和概念混为一谈,比如讨论“民主”时,认为追溯词源便等同于解释概念。然而,当诉诸人工智能处理自然语言时,事情远比这复杂。机器将暴露出一些我们之前未曾重视的哲学问题,促使我们重新审视语言如何构建现实。
例如,“逻各斯中心主义”这七个字究竟构成一个单一概念,还是其中的某些词能够独立成义?计算机擅长于符号处理,却缺乏“理解力”,无法判断概念的边界。词义是否仅仅等同于词典中的解释?一句话的意义是否隐藏在句子深处?这些问题在维特根斯坦的早期提出,而他的回答是否定的——句子的意义来自于它与其他句子的关系。这与当今一些基于上下文概率计算的语言模型在观念上相似。
这一观点正是语义网络(semantic network)研究的起点。问题在于,计算机能够识别“序列”——字母或数字的排列组合,却无法自主识别语义的边界。这便是剑桥语言研究小组在早期实验中所面临的挑战。他们很快意识到,单纯从技术层面探讨机器翻译并不足以解决根本问题,必须回到哲学层面,回归维特根斯坦的思考,尤其是他在 20 世纪 30 年代于剑桥大学教授的晚期思想。这些思想后来被整理成《蓝皮书》《棕皮书》和《哲学研究》等著作,研究小组创始人马斯特曼曾直接参与《蓝皮书》的整理。然而,后人常常只记得马斯特曼是人工智能的开创者,却遗忘了她与维特根斯坦的哲学传承。
我在 2022 年采访了当时唯一健在的剑桥语言研究小组成员约里克·威尔克斯,他保存并整理了一批马斯特曼和该小组的档案,临别时将其交给我保管,而第二年他便去世了。马斯特曼曾带领小组成员系统研读维特根斯坦的著作。1953 年,维特根斯坦最器重的女学生安斯康姆编辑并出版了他逝世后的重要作品《哲学研究》;次年,马斯特曼在英国亚里士多德协会会刊上发表了一篇重要文章《词》,这是对维特根斯坦思想的直接回应。
对于维特根斯坦在早期著作《逻辑哲学论》中提出的语言图形理论,马斯特曼认为维特根斯坦的探索尚不够深入。她主张,要推进这一理论,必须 在真实存在过的基于图像原则的语言中寻找实例,而古汉语则是最适合的例子,应尝试理解汉语如何构建其语义网络。
当时小组中有一位重要的英国学者韩礼德,他曾是王力的学生,并在剑桥教授中文,对小组的工作发挥了关键作用:帮助大家理解 中文为何能成为哲学资源,并思考如何在机器上实现语言的图形理论,为机器翻译奠定了基础。此外,韩礼德的系统功能语言学对早期美国人工智能研究也产生了深远影响,特里·威诺格拉德在麻省理工学院开发的著名自然语言理解程序 SHRDLU,便深受韩礼德理论的启发。
在此后二十年中,马斯特曼领导小组进行了大量人工智能实验,从成功的语义网络,到机器中介语及机械同义库。从谱系上看,现今人工智能中的向量空间研究与他们当年的探索存在明显的延续性。然而,关键并非在于他们是否“预先做过”当今的研究,而在于驱动他们的并非单纯的技术目标,而是哲学问题。他们真正关心的是:能否在机器上进行哲学思考,从而揭示语言中一些连维特根斯坦本人都未能完全触及的问题。可以说,哲学在早期人工智能研究中的作用,并不是为了建立所谓的“人工智能哲学”。这个概念本身值得质疑——如果它是真正的哲学,不应被限制于“人工智能的”范畴;哲学就是哲学。剑桥语言研究小组试图在早期人工智能实验中探讨维特根斯坦提出的一系列基本问题:什么是家族类似性?词语与图案是否有明确的界限?语言或符号的图形理论是否成立?如果这些理论无法在计算机上得到验证,或许本身就存在缺陷。因此,我的研究重点不仅在于为人工智能提供一种新的叙事框架,这不仅是科学史的问题,更关乎哲学的实践。
德里达的《论文字学》书名是否译错了?
重新审视西方哲学与人工智能的交汇
刘禾教授的最新影像(图:远读批评中心)
丁雄飞:您提到,马斯特曼被视为“第一位将对西方形而上学的批判推向超越字母书写限度的现代哲学家”。她在人工智能实验室中对逻各斯中心主义的批判,甚至比德里达的解构更为激进。这是基于什么理由呢?
刘禾:马斯特曼认为,维特根斯坦所提出的哲学问题之所以引人注目,部分原因在于它们能够突破心物二元论这一形而上学的基本限制。许多哲学家,包括德里达,均意识到这一点。然而,德里达在十多年后才开始探讨如何走出逻各斯中心主义的问题。他并未阅读过马斯特曼的著作,也未关注人工智能与语言实验的研究,因此他并不知情,早在他之前,已有学者在不同的道路上走得更远。
德里达的经典著作《论文字学》的中译本为《论文字学》,我认为这一翻译存在严重的 误译。“Grammatology”的更为恰当的翻译应为“文迹学”。在《弗洛伊德机器人》的译本中,翻译者何道宽先生采用了我的这一建议。德里达所关注的并非单纯的文字,而是所有能够留下印迹的事物,包括非文字性的印记,比如 DNA 和记忆的痕迹,这些印记可能是可见的,也可能是不可见的。这一点与中文语境中的“文字学”几乎没有直接关联,后者是专门研究汉字系统的学术领域。
德里达真正关注的是 如何从西方形而上学的内部,尤其是从语音中心主义的束缚中解脱出来。他所选择的切入点是字母书写留下的印迹。解构的过程正是借助这些印迹揭示并动摇可见与不可见之间的关系。在这一关系中,他对语音中心论提出了诸多质疑:字母仅仅是声音的书写吗?为什么声音会比书写更接近真理?德里达提醒我们,强调声音与真理紧密相连的观点,实际上是字母书写使得声音得以被辨识。在这种张力下,他的工作超越了传统的文字学或语文学的范畴。
德里达的这项工作始于 1960 年代,他首次明确探讨文迹学是在 1965 年发表的一篇书评中,评论的对象是法国考古人类学家勒鲁瓦 - 古尔汉(André Leroi-Gourhan)的两卷本著作《手势与言语》(Le Geste et la Parole)。
这本书至关重要,它探讨了手势、技术与语言的演变,从史前的岩画延伸至现代的基因编码。尽管德里达对逻各斯中心主义和语音中心主义提出了强有力的批判,但他也认为,真正的“外部”是不可及的。在我看来,这是一种退缩和懒惰的表现:为何不设想超越形而上学?难道拼音字母的世界就是唯一可知的世界吗?显然不是。德里达虽然从形而上学内部批判形而上学,但这并非唯一的选择。世界上存在多种书写和符号方式,这对马斯特曼及维特根斯坦而言,意味着更多的可能性。
维特根斯坦并没有将注意力局限于拼音文字,他同样关注“之外”的问题,只是他的切入点是图像和几何符号,并对数字符号表现出极大的兴趣。在《弗洛伊德机器人》中,我提到德里达对数字的近乎敬畏的态度,认为数学语言不受语音中心主义的限制,具有形而上学的豁免权,并暗示像控制论之父维纳这样的学者,本可以利用数字来解消形而上学。然而,这一判断未必成立,数字并不一定能够消解形而上学。维特根斯坦曾批评罗素等人的命题逻辑,直言那是一种形而上学的幻象,对语言的理解根本是错误的。
相较之下,马斯特曼及其剑桥语言研究小组在 1950 年代就已尝试多重突破逻各斯中心主义。他们在实践中论证并扩展了维特根斯坦的见解。维特根斯坦常通过实例启发思考,而马斯特曼等人面对机器上的语义网络问题,虽然认为其论述极为重要,却也显得模糊,必须将其转化为可测算的形式。在这一过程中,他们发现汉字提供了独特的资源。但不能简单地说汉字本身就能解构形而上学。他们通过“字”(马斯特曼文章中用的是韦氏拼音 tzu)重新界定语言单位。这里的“字”并非具有文化属性的“汉字”,而是一个哲学概念,乃是一种表意符号。“概念”的边界模糊,难以直接运算;而“字”则可以被纳入计算机运算。
因此,我认为德里达的工作并未走得太远——这并不是谁更“激进”的问题,而是马斯特曼的哲学探索带来了切实的影响:它推动了人工智能的发展,且其影响延续至今。成千上万的人在日常交流中产生了语言数据,其中哪些词的使用频率最高,哪些最低,哪些词更频繁地组合在一起,哪些组合较少——通过对语言现象的统计,语义网络的面貌逐渐清晰。正是统计方法推动了机器翻译的突破,而这一突破又反过来揭示了语言使用的规律,从而印证了维特根斯坦的洞见。
人工智能与哲学的新思考
丁雄飞:许多关于人工智能历史的叙述将其发展划分为两大方向:一方面是强调符号与逻辑推理的经典人工智能(Good Old-fashioned AI),另一方面是注重大数据的自适应机器学习(adaptive machine learning)——二者分别对应符号主义(symbolism)与联结主义(connectionism)两种主要的技术范式。在您的论述中,机器翻译的历史似乎也呈现为类似的两条路径:一条经由乔姆斯基,追溯到逻辑实证主义,强调句法逻辑;另一条则经由马斯特曼,追溯到维特根斯坦和日常语言学派,强调语义语用和自然语言数据。您将机器翻译的成功归结为后者的胜利,并将其视为一次反逻各斯中心主义的哲学事件,因此这也是 AI 共同体内部“反形式主义者”对“逻辑形式主义者”的胜利,是“字”的表意想象战胜“词”的表音书写。您所强调的哲学维度,是否正是通行的 AI 历史叙述所忽略的关键环节?
刘禾:确实如此,语义网络的思路与乔姆斯基的句法分析截然不同。后者关注主谓宾结构,并由此建立命题逻辑等形式模型。但如果仅仅做句法或词汇层面的分析,而不涉及语义,机器翻译基本上是无效的,根本无法称之为“翻译”。因此,曾经有一段时间,许多机器翻译项目停滞不前,被普遍认为前景暗淡。研究者们不得不直面语义问题。事实证明,从语义入手才是机器翻译唯一可行的路径。研究者依靠大数据、语料库和数学模型,试图界定语义的边界。
相较之下,语言学家往往会拿一个孤立的句子进行句法分析,探讨其深层含义——这并不能反映人类真实的交流状态。
罗素在讨论命题逻辑时常用古老的悖论“我在撒谎”进行分析。维特根斯坦则会问:这种句子在何种语境下会出现?在日常语境中,人们更多地会说“你在撒谎”,而非“我在撒谎”。维特根斯坦认为,这些逻辑学家在构造语言,仿佛马达在空转,他强调必须 回归真实的语言使用 。马斯特曼等人在这种理念下,尝试构建机器模型,通过统计语言数据来理解语言,考察语义网络,随后再考虑语言之间的关系,进入机器翻译的实践。因此,他们的首要任务是哲学工作,只有在哲学上澄清问题,才能处理技术问题。因此我强调, 技术本身并不自然而然具有哲学意义,需要经过哲学上的甄别:什么是重要的?什么是次要的?哪些元素之间存在联系?哪些元素可以被机器计算?哪些则不然?
顺便提一下,所谓人工智能的“新旧”之分,但“新派”未必真正新鲜。如今,联结主义受到极大的推崇,然而,神经网络最早源于控制论。1943 年,麦卡洛克(Warren S. McCulloch)与皮茨(Walter Pitts)发表了一篇具有深远影响的论文《神经活动中内在思想的逻辑演算》(A Logical Calculus of the Ideas Immanent in Nervous Activity),提出机器与人脑在某种程度上存在共性,神经元的行为模式可以类比于机器的逻辑运算,即“开”与“关”的二元状态。今天,这种思维之所以显得前沿,正是因为现今计算机在计算能力、存储容量和运算速度等方面远超往昔,从而使这些模型得以更充分地实施。

点击上图,将《弗洛伊德机器人》加入购物车
丁雄飞 :在您讨论《帝国的话语政治》时提及《马氏文通》,您认为其灵感来源于《唯理普遍语法》(Grammaire générale et raisonnée)。后者的目标是探索“普遍语法规律”,这一思想与乔姆斯基的“深层结构”理论相互关联。然而,最近的研究中,您似乎借鉴了马斯特曼的观点,指出了一种新的普遍性:“表意原则在所有语言的运作中普遍存在”。尤其令人印象深刻的是您在《帝国的话语政治》中对“六书”原则的阐述——虽然可用于造字的部首数量有限,但它们的组合方式却是无限的。这一观点与您在 AI 相关论文中提到的马斯特曼的“字”的组合逻辑(combinatory logic)形成了呼应。考虑到您在这两方面的论述已跨越二十年,不妨理解为您通过两个“马氏”对比了两种截然不同的普遍性?甚至可能区分出“真普遍”与“假普遍”,以及“好普遍”与“坏普遍”?
刘禾 :您提到的这两者之间的关系极为重要,您的理解非常深入。之前,我所探讨的马建忠的章节标题为“语法的主权身份”(The Sovereign Subject of Grammar),旨在历史语境中反思汉语为何需要“语法”,以及“语法”本身的重要性。与此相对,马斯特曼等人则关注句子的“逻辑”,而非其“语法”。
从这一视角来看,《马氏文通》的贡献可以视为对西方形而上学及逻各斯中心主义的妥协。这种妥协带来了深远的影响:马建忠试图使用西方语法的框架来讲解汉语,但其研究所依赖的并不是活语言,而是“字”或“文”的层面——《马氏文通》中引用了大量古籍的经文。马建忠试图从中提炼出语法,这导致了中文的“字”与拉丁文的“verbum”或英文的“word”之间的混淆,构建了一种虚假的对等关系,从而形成了一个极具误导性的衍指符号(super-sign)——“字 /word”。结果就是,文字与语言被混为一谈,两个本应有区别的系统被混淆,这是一个无法成立的等式,但马建忠对此并未深入思考。此后,中国的语法研究便在这样的基础上展开,尽管后来的研究者意识到其中的不妥,试图用新创造的“词”来替代“字”与“word”的对应关系,但根本问题并未得到解决。
西方语法引入汉字领域后,造成了大量的混乱与伪问题,令学者争论不休。例如,研究者们致力于分析汉字的“词性”或句子成分,但由于汉字的高度灵活性,往往无法被这些固定的语法分类所限制。这一误解的根源可以追溯到马建忠的宗教背景和他的传教士老师。长期以来,传教士将汉语视作单音节语言,令人惊讶的是,这一论断至今仍为一些语言学家所接受。这显然是对“文”与“言”的混淆。正如赵元任通过声谱仪所示,任何方言的发言都是连贯的语流,而非孤立的音节。传教士之所以产生汉语是单音节语言的错觉,正是因为他们学习汉语时从认字开始,而大部分汉字确实对应一个音节,因此他们误将书写单位的特征当作口语的特征。说“汉字是单音节的”或许在经验上成立,但说“汉语是单音节的”则完全站不住脚。

刘禾著《帝国的话语政治》2014 年修订译本
杨立华 译
与此形成鲜明对比的是,马斯特曼敏锐地洞察到,真正的普遍性并不在声音的范畴:不同语言和方言在声音上存在隔阂,无法相互理解。真正的普遍性应在表意的领域中寻找。因此,马建忠和马斯特曼之间的差异愈发明显:马建忠接受了传教士对汉语和汉字的误解,认为语法具有普遍性,这与乔姆斯基通过句法寻求普遍性的思路相似。而马斯特曼则发现汉字的潜能,认为汉字作为表意符号,具备类似数字的组合逻辑,这与罗素等人思考的命题逻辑截然不同。在汉字系统中,“文字”与“数字”都以“字”来表示,这样的涵盖范围更广,因此更具抽象性与普遍性。
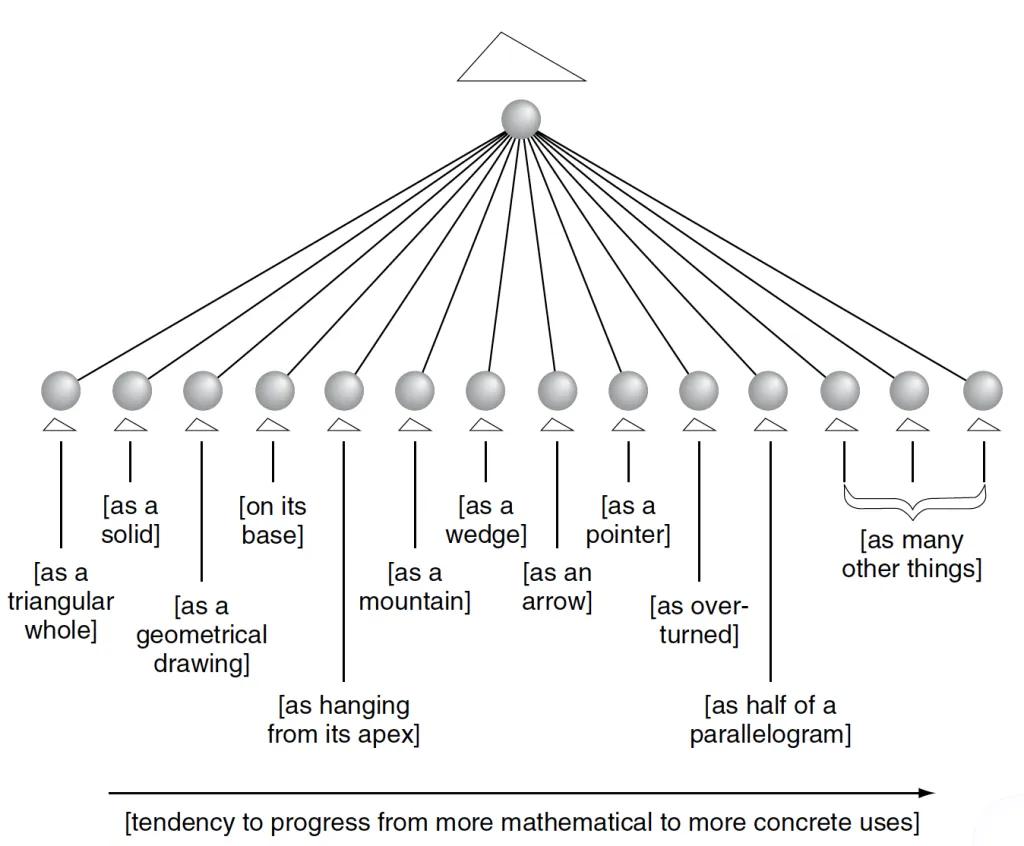
马斯特曼《扇簇与头符》(Fans and Heads)一文中的示意图,呈现了维特根斯坦所示三角形图标(icon)的多重语境 / 意义。
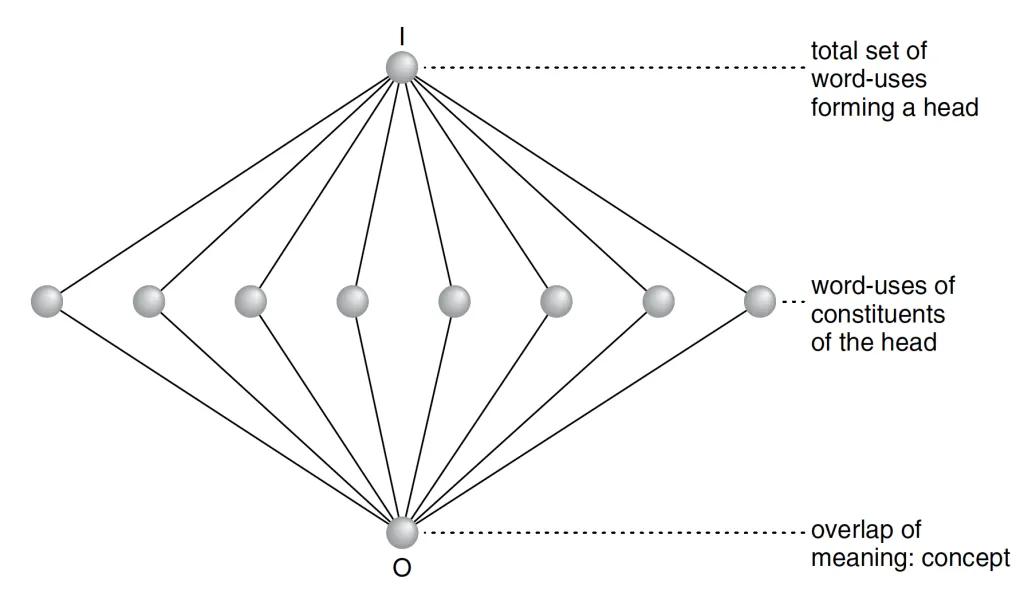
马斯特曼《翻译》(Translation)一文中的“头符”数学建模示意图,呈现了“头符”的“格”(lattice)结构:上层为一个“头符”集合,中层为词的各种具体用法,下层为词义的交集,即共享的意义重心 / 概念。这种可计算的语义结构,便于机器翻译和自动分析。
丁雄飞 :在您的论文中有一个引人深思的问题:“机器中介语是否可以被视为普遍语言?”然而文中并未给出明确的答案。您对此有什么看法?关于基于中介语(interlingua)的机器翻译与莱布尼茨的“普遍语言”(characteristica universalis)构想之间的联系是怎样的?
刘禾 :自十七世纪以来,尤其是莱布尼茨之后,欧洲思想界始终在进行寻找普遍语言的探索。这种追求背后往往隐藏着神学动机。他们所设想的普遍语言,亦可视为一种原始语言(primitive language),这里的“原始”并不意味着落后或野蛮,而是指在神学框架下最为古老、根本的语言,是对《圣经》中提到的“亚当语”的想象。起初,他们认为这种语言存在于古埃及;随着传教士抵达中国并报告他们似乎发现了普遍语言,这种热情再次被激发。
需要注意的是,历史上所谈论的普遍语言与我们讨论的中介语应有所区分。欧洲人对普遍语言的探索,是在神学或科学主义的驱动下所形成的历史文化现象。而中介语则是一种数学结构,作为任意两种自然语言之间的转换代码。然而如果在当今语境中探讨“普遍语言”的含义,我认为它已不再是我们通常理解的“语言”,而是一种“通讯代码”(communication code)。在《弗洛伊德机器人》中,我讨论了克劳德·香农(Claude Shannon)提出的“机识英语”(Printed English),他希望将其发展为一种“通用代码”(universal code)。在机器主导的时代,这种数学化的代码才是真正获得普遍性的。
丁雄飞 :根据您的描述,香农为信息系统创造了表意英语,将英语转变为统计符号系统,从而为电子书写奠定了基础。这似乎表明香农的工作与马斯特曼的思想之间存在高度的关联性。而在您所著的《弗洛伊德机器人》中,您提到香农与图灵的工作是平行的。是否可以认为,这三位来自不同领域的思想者,共同推动了您所称的“二十世纪中叶表音书写向表意转向”的进程,这一转向恰好定义了整个数字媒介的未来?
刘禾 :确实可以将图灵、香农和马斯特曼视为二十世纪中叶思想界的三个重要节点。尽管他们的研究方向各有不同——图灵专注于现代计算机的理论框架,香农则致力于通讯网络的构建,而马斯特曼关注语义网络——但他们都意识到相同的核心问题:为了使机器有效运作,必须创造一种机器能够识别的、基于表意逻辑的代码。
图灵在 1936 年发表的论文《论可计算数及其在判定问题中的应用》(On Computable Numbers, with an Application to the Entscheidungsproblem)中,为可计算性提供了严格的数学定义,奠定了现代计算机科学的基础。接着,他在 1950 年的文章《计算机器与智能》(Computing Machinery and Intelligence)中,进一步探讨了机器是否具备思考能力及智能潜力。
在三位学者中,马斯特曼是唯一清楚使用“表意”这一理念的人。相对而言,香农虽然作为一名工程师并未在哲学或概念的层面上进行总结,但他的实践在另一个维度上同样印证了相似的结论。他的核心发现源于对摩尔斯电码的深入分析:他意识到电码不仅有长短不一的信号,更为重要的是其中所包含的有意义的停顿。如果没有停顿来划分信号,信息就无法形成。香农的创新在于他将这一发现应用到字母系统中,创造出一套由二十七个字母组成的“机识英语”。这个额外的字母,就是“空格”。不同于传统的“空白”,这个空格实际上是一个表意符号,旨在为连续的字母流设定界限,从而界定字母或“词”的单位。例如,字母组合“C-A-T”之所以可以被认作一个独立的单元,正是由于前后空格的界定。因此,香农在字母表中正式引入“空格”这一字符,实际上实现了一次深刻的转变:他通过添加一个纯粹表意的结构符号,将原本表音的系统转变为可被机器读取的数字化表意系统。
香农基于电报和通信实验中获得的关于“空格 / 表意”的发现,与马斯特曼通过汉字得出的“表意逻辑”形成了共鸣。虽然汉字不依赖空格,但作为表意符号的“字”本身就具备组织意义和构建语义网络的功能。无论是香农还是马斯特曼,都证明了机器处理信息的基础在于识别和操作具有清晰边界的表意代码单元,而并非单纯模拟人类语言的语音或语法。《弗洛伊德机器人》虽然在十五年前便已问世,但它与我目前的研究依旧密切相关。
点击上图,将《弗洛伊德机器人》加入购物车
丁雄飞 :在您的论文中,您对塞尔(John Searle)的“中文屋”思想实验提出了批评,指出其背后存在一种“不对称的互斥逻辑”,并将其视为“他者心灵形而上学”的复活。这与您之前在翻译研究中提到的“话语运动的方向性”及“不均衡分布的话语场”显得颇为相似。您为何在讨论人工智能的核心内容时,特意对“中文屋”进行深入分析呢?
刘禾 :我之所以关注“中文屋”的主题,是因为这个思想实验在人工智能的教学和研究中造成了极大的误导。它不仅歪曲了公众与学术界对人工智能的认知,还引发了认知科学领域长达二十年的低质量争论。在西方哲学中,构思思想实验是一种常见的方法,而这些实验往往以一个可疑的前提开始——即从无法理解文明语言的野蛮人出发——以此进行推论。当“中文屋”以类似的方式出现时,我认为有必要揭示其背后的问题。这个思想实验及其所代表的哲学方法,实际上以一种更加隐秘且不易察觉的方式延续和维护了种族主义偏见。它假借探讨“图灵测试”的科学名义,巧妙构建了一套论述。尽管许多人可能直觉地感受到其中的不妥,却选择沉默。这种情况并非偶然,而是源于一个历史悠久且根深蒂固的西方哲学传统,其核心特征在于对自身思想优越性的坚信。因此,围绕人与机器的讨论自始至终都陷入了这个充满偏见的框架。我的批评并不仅仅针对塞尔个人,而是针对他背后的那种自信且始终自视优越的哲学传统。

刘禾编《世界秩序与文明等级》(2016)
人工智能是否是人类无意识的产物?
丁雄飞 :在您介绍马斯特曼时,您引用了威尔克斯的观点:马斯特曼时常提到“罗热的无意识”(Roget’s unconscious),意指“词汇之间的交叉指涉包含了一般规律”。这与《弗洛伊德机器人》中讨论的“控制论无意识”和拉康理论似乎有着呼应。我的疑问是:在您撰写《弗洛伊德机器人》的阶段,您对“将人脑视作计算机进行控制论新规划”的看法基本持批评态度,而在“表音书写的表意转向”框架下,您对这些技术则显得较为积极,这之间是否存在微妙的矛盾?
刘禾 :我们首先来探讨机器无意识的问题。多年来,人们一直在争论机器是否能够实现认知,获得与人类相同的智能。而这一争论的焦点,往往被设定为“机器是否能获得意识”。这个问题本身就蕴含一个根本性的假设:它将意识视为衡量智能的唯一标准,并预设了一个以自我意识为中心的“人”作为参照点。这种视角的根本问题在于,它完全忽视了无意识在人类行为中的重要作用。早在控制论与人工智能兴起之前,弗洛伊德与拉康的精神分析理论便已揭示:推动人类行为的主要动力并非意识,而是无意识。
拉康的洞见尤其重要。他对控制论的研究充满兴趣(例如当时关于鲸鱼和海豚如何传递信息的研究),因为这些自动化的信息系统恰恰可以类比为人类的无意识。拉康曾言—— “无意识如同语言一样被结构化”“无意识是他者的话语”——这说明无意识并非隐藏在大脑深处的神秘事物,而是一个外在的、社会性的、自动化的结构。符号秩序以及社会性的语言和规则被不断执行,最终驱动我们形成自动反应,例如口误和失言便是无意识的表现。从这个角度看,机器的运作逻辑与人的无意识展现出惊人的相似性。机器的自动运转,就如同语言符号系统的自动运作。然而,在控制论和人工智能的主流研究中,“无意识”始终是科学界刻意回避的对象——尽管像劳伦斯·库比(Lawrence S. Kubie)这样的精神分析师在核心圈内。但这种被压抑的内容却不断干扰他们。因此,我认为,机器真正能够与人展开深刻对话,并成为我们有效思考的对象,恰恰是在无意识的层面。
这也引出了对控制论的批判性审视问题。我的书中确实包含了 对控制论的诸多批评,尤其是针对其背后隐藏的帝国主义梦想与冷战思维。所谓的“弗洛伊德机器人”群体,正是在控制论无意识的驱动下,全球范围内寻求军事征服与压迫,以满足对他者的控制欲望。然而,识别并批判这些问题,与深入理解其理论贡献并不冲突。就如同现在有些人简单地将人工智能视为洪水猛兽,但我认为这种立场若要彻底贯彻,就必须同时反对所有现代科技,因为它们无一例外地都与复杂的、不干净的权力系统(如帝国征服)密切相关。
关键在于,我们不能因其在伦理或政治上产生争议,就放弃对其深入研究的机会。一个理论或发明,可能同时服务于多种目的。例如,香农在二战及冷战初期参与密码学与保密通信的研究,但这并未妨碍他在此过程中提出奠基性的信息论思想。我们不能因为它们的历史用途而忽视这些发现和发明。毕竟,只有在深入理解之后,我们才能有效地进行批判。
丁雄飞 :根据您的界定,“弗洛伊德机器人”指的是一种不可避免的人机互为模拟的无限循环关系,因此也无法摆脱控制论无意识的存在。在这种背景下,当前的对话生成式预训练模型(如 ChatGPT)或许可以被视为其最新的支配形态。有批评认为,这类对话机器人善于无原则的迎合,容易将普通人的观点固化,从而加剧社会意识形态的僵化,您对此有何看法?
刘禾 :尽管 ChatGPT 于 2022 年底正式发布,但围绕它的许多讨论早在半个多世纪前就已有迹象。1966 年,麻省理工学院的科学家约瑟夫·维森鲍姆(Joseph Weizenbaum)开发了第一款具有广泛影响力的聊天机器人 ELIZA。维森鲍姆本人作为模仿心理治疗师的“DOCTOR”脚本设计者(ELIZA—A Computer Program for the Study of Natural Language Communication between Man and Machine),对人们对 ELIZA 的拟人化热情提出了尖锐的哲学批评。他指出,人类用户之所以能够与机器对话,并非因为机器具备智能,而是由于一种自我投射的心理机制。为了系统地批判同事们在这种技术乐观主义下的盲目,他撰写了《计算机能力与人类理性》(Computer Power and Human Reason: From Judgment to Calculation),最终选择与自己开创的领域保持距离。
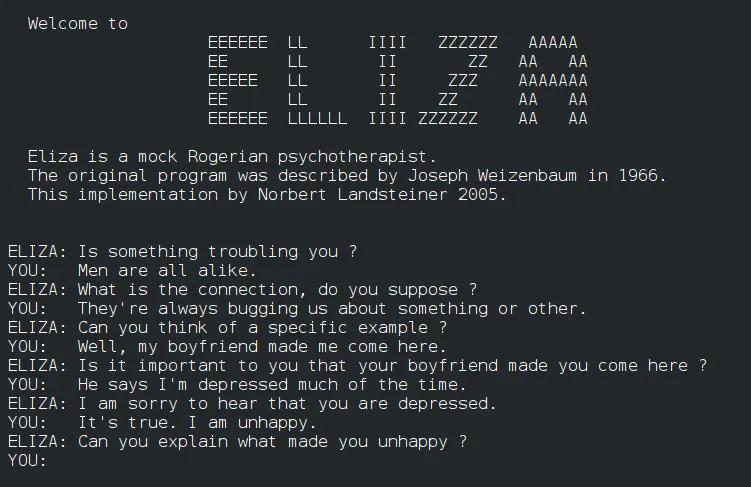
与 ELIZA 对话
维森鲍姆的洞察与拉康的理论相互契合。拉康曾指出,当你在电话中与他人交谈时,首先听到的是自己早已知道的内容。同样,用户与 ChatGPT 的互动,正如与 ELIZA 的互动,是一个将自身的愿望、幻想与期待投射到机器上的过程。机器生成的文本因语言本身的模糊性,为用户提供了广泛的解读空间,就如同人们对算命先生的预言,最终看到的只是内心早已存在的答案。从这个角度来看,ChatGPT 的强大在于更加高效、全面地反映和放大了人类的自恋。即便算法本身并未意图迎合,用户依然能够在模型的回答中找到符合自己期待的证据。当我们穿透当前对聊天机器人的过度宣传,重新审视 1966 年的 ELIZA 时,会明白构成这场人机互动幻觉的所有基本元素,其实在过去的半个多世纪中并未发生改变。