共计 3244 个字符,预计需要花费 9 分钟才能阅读完成。

本文的主要作者是清华大学的博士生张清杰,他专注于大语言模型的不当行为与可解释性研究;通讯作者为清华大学的邱寒副教授,其他合作者则来自清华大学、南洋理工大学及蚂蚁集团。
假如我们的教材中充斥着粗俗的语言,难道还能够掌握好语言吗?这一荒谬的问题竟然在目前最先进的 ChatGPT 系列模型的学习过程中出现。
来自清华大学、南洋理工大学和蚂蚁集团的研究者们发现,
GPT-4o/o1/o3/4.5/4.1/o4-mini 的中文词汇中,污染率高达 46.6%,其中包括如「波 * 野结衣」、「* 野结衣」、「* 野结」、「* 野」、「大发时时彩」、「大发快三」、「大发」等与色情、赌博相关的词元。(详见下图。)
研究团队还分析了 OpenAI 近期推出的 GPT- 5 和 GPT-oss 的词汇表,发现它们的中文 token 也没有发生变化。
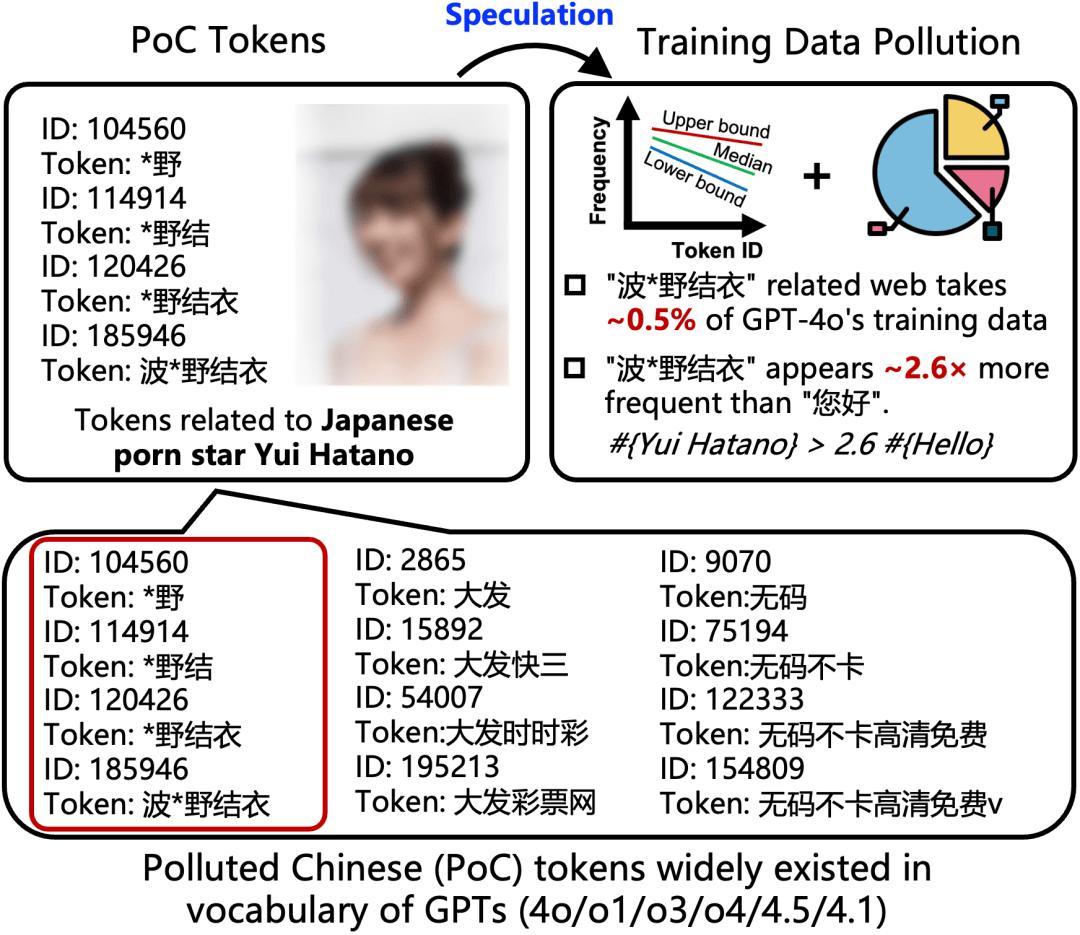
图 1:GPT-4o/o1/o3/4.5/4.1/o4-mini 的中文词汇污染率达到 46.6%,主要涉及色情和赌博内容。
研究团队认为,这种情况的发生源于大规模模型预训练所使用的互联网数据中不可避免地包含了污染内容,这导致构建的大语言模型(LLM)词表中也混入了污染词。那么,这些污染词究竟会对 LLM 的性能产生怎样的影响?与污染数据之间的关系又是如何呢?
为了对 LLM 的中文词汇与数据污染问题进行系统性的研究,研究团队首先 对污染词进行了定义与分类 (Polluted Chinese tokens, PoC tokens),并分析了这些词对 LLM 性能的影响。此外,为了高效识别不同 LLM 词表中的 PoC tokens,研究团队设计了一款 中文污染词检测模型 ;最后, 通过中文词汇表的污染情况有效评估数据的污染程度,为治理污染数据提供了轻量化的解决方案。

- 论文标题:Speculating LLMs’Chinese Training Data Pollution from Their Tokens
- 录用会议:EMNLP 2025 Main
- 项目网站:https://pollutedtokens.site/
值得一提的是,这项研究于 2025 年 5 月 29 日在清华大学基础模型学术年会上由邱寒教授首次展示,并提出了应对 10T 级大语言模型训练语料库污染数据的治理技术。
央视在 2025 年 8 月 17 日的报道中也强调了 AI 数据污染的潜在风险。
中文污染词的概念、种类及其影响
本项研究的首要任务是组建一个由六位跨学科专家组成的标注团队,涵盖哲学、社会学、中文语言学及计算机科学等领域,这些专家共同对先进的 ChatGPT 模型中文词表进行了污染词的标注,进而明确了中文污染词的概念与分类,为今后的研究奠定了基础。
概念:中文污染词(Polluted Chinese tokens, PoC tokens)是指在 LLM 词表中,按照主流中文语言学原则编制的含有不合法、不常见或不常用的中文词汇(通常由两个或两个以上的字组成)。
种类:中文污染词主要可以分为以下五大类:
- 成人类内容,如「波 * 野结衣」。
- 在线博彩,比如「大发彩票网」。
- 网络游戏,例如「传奇私服」。
- 视频观看,比如「在线观看」。
- 异常内容,例如「
自动化识别中文污染词的检测技术
研究团队致力于将中文污染词的识别与分类拓展至更多的 LLM,通过微调污染较少且中文能力出色的 GLM-4-32B,开发出一款自动化的中文污染词识别模型。
值得注意的是,中文污染词往往难以辨识(例如「青青草」虽然表面正常,但其 Google 搜索结果却与色情网站相关),即使是专业的中文语言学者也难以判断某个词是否被污染,及其具体的污染类别。
因此,研究团队为识别模型设计了一种网络检索机制,针对每一个待检测的中文词返回 10 条 Google 搜索结果,以作为判断其是否污染的背景信息。此外,模型还通过专家标注的结果进行微调,最终实现了 97.3% 的识别准确率。
如图所示,研究团队使用此识别模型对 23 个主流 LLM 的 9 个词表进行了中文污染词的检测。发现不仅是先进的 ChatGPT 系列模型,其他 LLM 的词表中也存在中文污染词。其中,成人内容、在线赌博和奇怪内容占据了大部分。
然而,之前的 ChatGPT 模型版本(GPT-4/4-turbo/3.5)仅包含极少数表征多个中文字的 token,并未涵盖中文污染词。

图 4:Qwen2/2.5/3 和 GLM4 的部分中文污染词。
污染追踪:通过词表评估数据的污染程度
鉴于词表污染反映了训练数据的污染,研究团队进一步设计了一套污染追踪方案,通过反向估计 LLM 的词表来评估训练数据的污染情况,为大规模数据治理提供了一种轻量化的解决方案。
大多数 LLM 的词表是基于 BPE 算法构建的。简单来讲,BPE 算法会对语料库中词汇的频率进行统计,将频率较高的词汇排在词表的前面,从而实现词 ID 的小值对应高频词汇。而通过词表进行污染估计实际上是对 BPE 算法的逆向推导,但由于一个词 ID 可能对应多个词频,逆向结果并非唯一,仅能给出词频的估算范围。
因此,研究团队结合经典语言学中的 Zipf 分布和上下确界理论,利用分位数回归方法在开源语料库上拟合了词 ID 与词频之间的经验估计。
下图显示,这种经验估计有效地拟合了词 ID- 词频分布的上下界,并且落在理论上下确界之间,因此被视为一种有效的污染追踪方法。
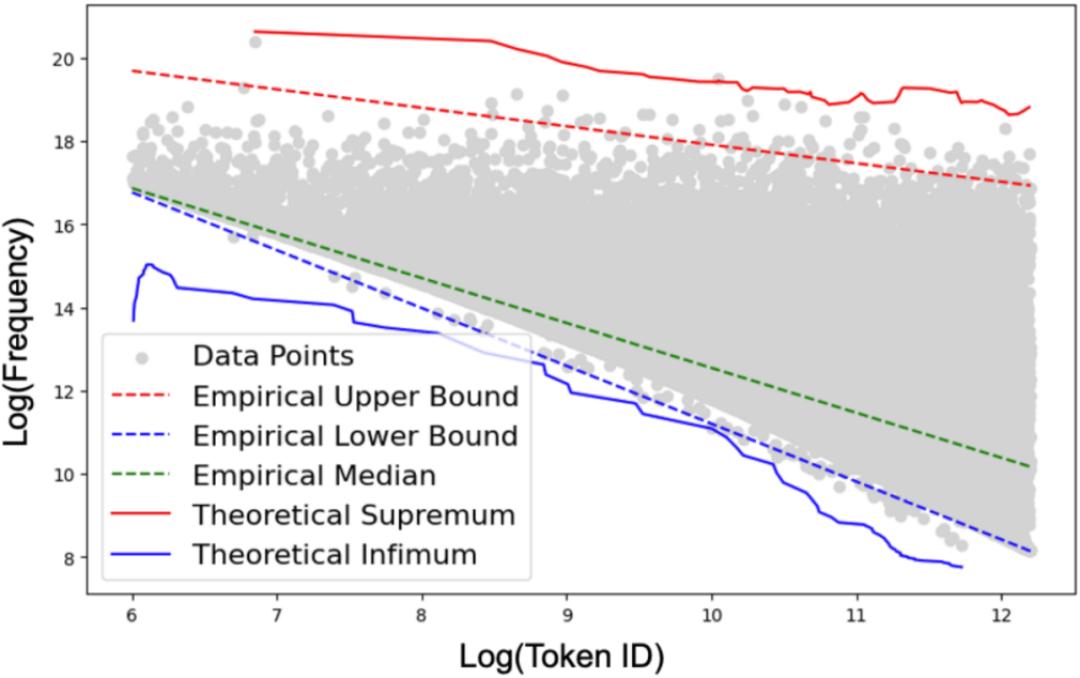
图 5:词 ID- 词频的经验估计有效拟合了分布的上下界,并且落于理论上下确界之间。
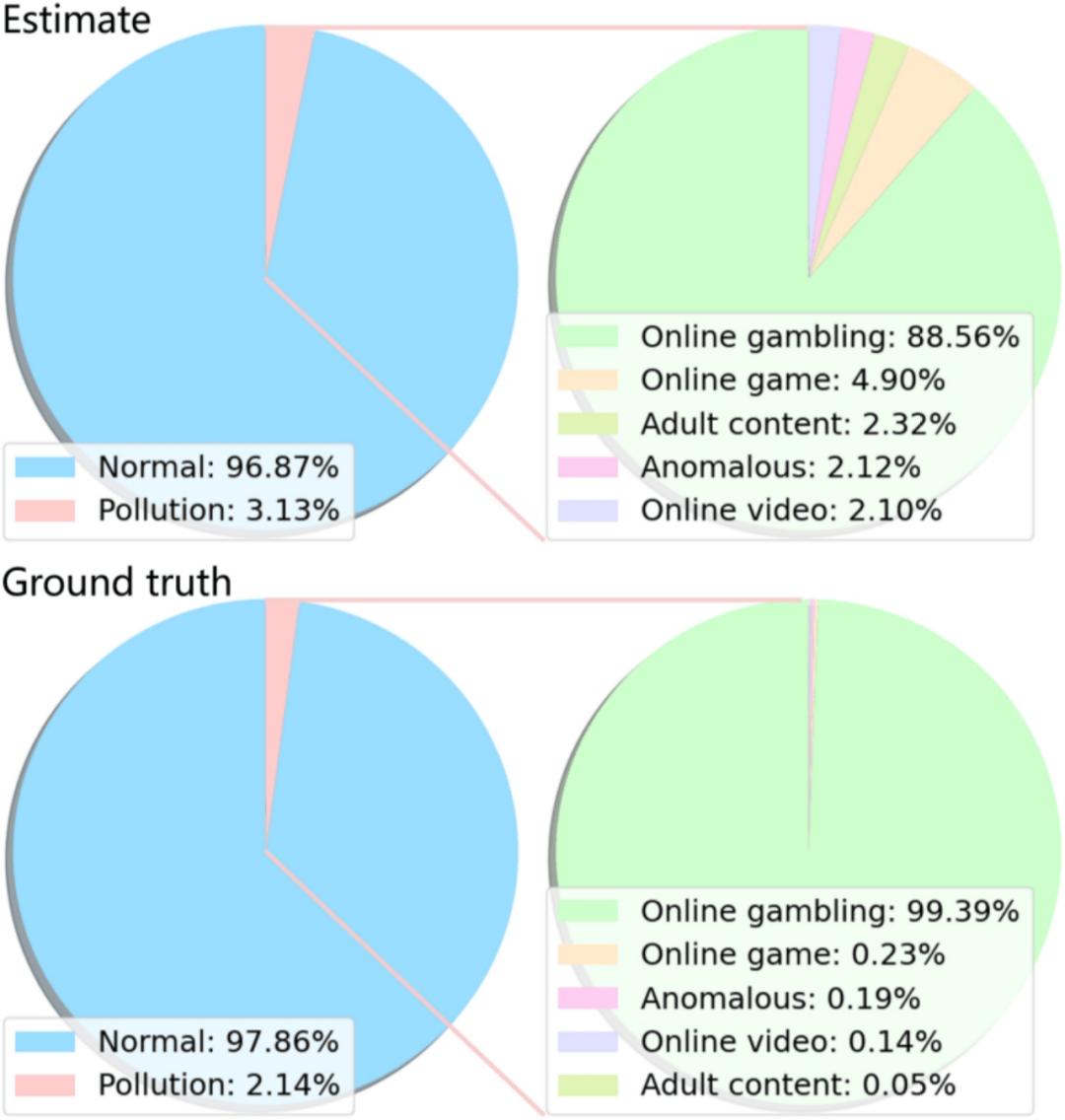
在这种经验估计的基础上,研究团队对开源语料库 mC4 的数据污染进行了评估,并与真实值进行了比较。如下图所示,该估计方案对整体数据污染的估计相对准确,但在特定污染类别的估计上仍有提升空间,这主要是因为特定污染类别的样本数量较少,其分布特征在大量语料库的统计中被削弱。

图 6:开源语料库 mC4 的数据污染估计及与真值的比较。
进一步,研究团队还评估了 GPT-4o 词表中出现的中文污染词「波 * 野结衣」在训练数据中的污染情况。结果显示,与 GPT-4o 中文训练语料相关的页面占比高达 0.5%,是中文常用词「您好」的 2.6 倍。
由于 GPT-4o 的中文训练语料尚未开源,为了验证这一估计,研究团队在无污染的开源数据集中按照 0.5% 的比例混入与「波 * 野结衣」相关的页面,并利用 BPE 算法构建词表,模拟 GPT-4o 的构建过程。下图所示,该比例几乎准确地再现了 4 个相关词「* 野」、「* 野结」、「* 野结衣」、「波 * 野结衣」在 GPT-4o 词表中的词 ID。
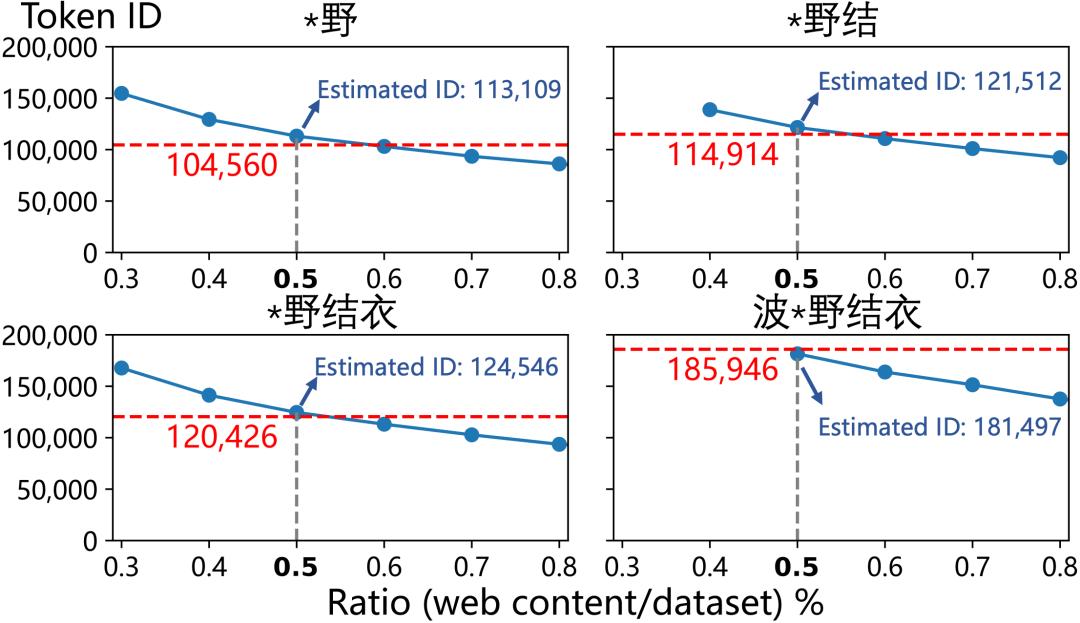
图 7:依据 0.5% 的比例融合「波 * 野结衣」相关页面,能在开源语料库中重现与之相关的四个词汇「* 野」、「* 野结」、「* 野结衣」、「波 * 野结衣」,这些词在 GPT-4o 词表中的词 ID。
未来展望:污染数据是否完全无益?
尽管污染数据可能会使大语言模型的词表中掺杂「污言秽语」,但这是否意味着污染数据一无是处呢?哈佛大学在 ICML 2025 上发表的论文《When Bad Data Leads to Good Models》指出,适量的污染数据在预训练中可起到对齐模型的催化作用。
该项研究建立在以下理论假设之上:如果预训练过程中有害数据过于稀少,有害表征将与其他表征混合,导致难以区分;而当有害数据适中时,有害表征则更容易被识别。
图 8:预训练包含适量有害数据与极少有害数据的对比:前者更能有效区分有害表征向量。
更进一步,研究团队在 Olmo-1B 模型的预训练中,依据 0 -25% 不同行为数据比例进行实验,并在推理阶段识别和抑制有害表征,以降低有害内容的输出。实验结果表明,适量(10%)有害数据预训练的模型,其有害性在应用抑制方法后最低,甚至低于未包含有害数据的预训练模型。
水至清则无鱼,适度的污染数据有助于模型的安全对齐。在确保安全对齐与防止过度污染之间找到平衡,正是未来污染数据研究亟待探讨的关键方向。
总结
最新的 ChatGPT 系列模型中,有 46.6% 的内容属于「污言秽语」,并且输入这些「污言秽语」会使模型出现错误的输出。基于这一现象,研究团队系统性地定义并分类了中文污染词,构建了自动识别中文污染词的模型,并对训练语料的污染程度进行了评估。综上,该研究期待 为 LLM 大规模训练语料的治理提供轻量化的解决方案。