共计 4083 个字符,预计需要花费 11 分钟才能阅读完成。

作者 | 徐豫
编辑 | 漠影
在 DeepSeek 的新时代,“开源”和“免费”成为了大模型领域的全新焦点,超越了“参数量”和“模型架构”的争论。
据智东西于 2 月 15 日报道,百度、DeepSeek、OpenAI、谷歌及 xAI 等 主要的大模型开发者接连宣布,其闭源的高端 AI 模型将转为开源模式 ,同时 主流 AI 产品将免费提供给用户使用。这一系列动作不仅标志着大模型竞争的白热化阶段即将到来,也意味着 AI 技术离普通大众的生活愈加接近。
在这场激烈的较量中,百度与 OpenAI 的竞争尤为突出,双方接连透漏新一代模型、深度搜索功能以及生成式 AI 工具的免费使用计划,并且都在积极推进开源计划。
在 2 月 14 日,百度 宣布将在未来几个月内陆续推出 文心大模型 4.5 系列,并指出新一代文心大模型将于 6 月 30 日正式开源,这标志着百度首次推出开源大模型。同时,市场传言称百度还将于今年发布文心大模型的5.0 系列。
在此之前的一天,百度也公开宣布,自 4 月 1 日起,文心一言将全面免费供用户使用 ,让用户能够在 PC 和 APP 端自由使用最新的文心系列模型。与此同时,OpenAI 的 CEO 奥尔特曼在 X 平台上发布了长文,透露将在数周或数月内推出 新一代 GPT-4.5 模型(内部代号为“Orion”)和GPT- 5 系统。
奥尔特曼在文中提到,ChatGPT 的免费套餐也将涵盖对 GPT- 5 的无限聊天访问权限。这意味着,用户不仅可以 免费使用 ChatGPT 的搜索功能,后续还将享受OpenAI 最新模型的免费服务。
在本月早些时候,谷歌 也宣布将开放其最新的 Gemini 2.0 系列模型。此外,马斯克在 2 月 14 日接受采访时表示,计划将在 一到两周内推出新一代的 AI 模型 Grok 3,其性能可能超越 GPT 系列,且极有可能 继续采用开源策略。可见,这些大模型制造商都在为这场竞争全力以赴,丝毫不打算让步。
此外,百度和 OpenAI 也计划逐步推出深度检索的相关功能。
OpenAI 方面表示,深度检索功能最初会为每月提供两次免费机会,Plus 用户每月可用十次,而所有 Pro 用户则可在移动和桌面 APP 上使用该功能。百度的文心一言深度搜索功能目前已在 PC 端上线,从 4 月 1 日起也将免费提供,APP 端的上线也在筹备中。
如今,大模型朝着免费、开源与开放的方向发展,背后是 技术进步导致的训练和推理成本显著降低。
在 2 月 11 日,百度创始人李彦宏在阿联酋迪拜的“世界政府峰会”上指出,“在过去,当我们讨论摩尔定律时,性能水平或价格每 18 个月就会减半。而现在,关于大型语言模型,我们可以说 每 12 个月推理成本降低超过 90%。”
OpenAI 的 CEO 奥尔特曼最近在博客中也表达了类似的看法。他指出,AI 的成本下降极大地促进了 AI 应用的增长。奥尔特曼指出,每年的 AI 使用成本下降约 90%,这也为更多用户接触 AI 技术创造了机会。
随着大模型的使用成本逐渐降低,不仅使得中小企业更容易进行本地化部署,还促使了更实用的大模型衍生品的开发;同时,也帮助普通人将 AI 产品融入日常生活,能够构建个性化的 AI 工具、产品及智能体,最终为整个 AI 生态系统注入新的活力。
那么,究竟是什么让大模型能够无偿提供服务?它们又是如何实现高性价比的 AI 计算能力?先进模型的优势又体现在哪些方面呢?通过深入分析百度在多个大模型开发方面的经验,我们归纳出自研芯片、数据中心、AI 计算平台以及推理技术架构的深度优化这四个关键因素。
一、文心系列率先出击,全面搜索功能即将上线
在经历了六个月的沉寂后,百度的文心大模型即将迎来升级。根据百度最新的消息,文心大模型 4.5 系列将在接下来的几个月内逐步推出。此外,市场上的传言显示,文心大模型 5.0 系列可能会在今年下半年发布。
在 2023 年 10 月,百度推出了文心大模型 4.0;去年 4 月,文心大模型 4.0 的工具版上线;而在去年 6 月,性能更强的文心大模型 4.0 Turbo 也正式上市。从 4.0 系列的发布节奏来看,百度似乎已经用实践证明了李彦宏所说的“创新的本质”。在他看来,创新的核心在于“如果能够降低成本,那么生产率必然会相应提升”。
有消息人士透露,文心大模型 4.5 和 5.0 将在 多模态能力 方面实现显著增强。与此同时,OpenAI 则计划将 o3 推理模型和多种 AI 技术整合到即将推出的 GPT- 5 系统中。
此外,文心大模型的 视觉智能能力 也是其一大亮点。基于这一点,百度或许将取代 OpenAI 和谷歌,负责国行版 iPhone 中 Apple Intelligence 的视觉智能功能。据外媒 2 月 14 日的报道,百度将担当“国行版”Apple Intelligence 所需的图像识别与检索功能。
目前,百度自主研发的 iRAG(基于图像的检索增强生成技术),结合了检索增强(RAG)技术和视觉智能,不仅能从百度搜索引擎中检索、比对大量图像资源,还能够通过文本生成更高质量、更加真实的 AI 图像,显著减少传统文生图技术中常见的“幻觉”现象。
实测结果显示,具备 iRAG 能力的文心大模型 4.0 生成的人物形象和动作 更加符合文字描述和物理逻辑 。此外,文心大模型 4.0 还能一次性生成 多张 AI 图像。
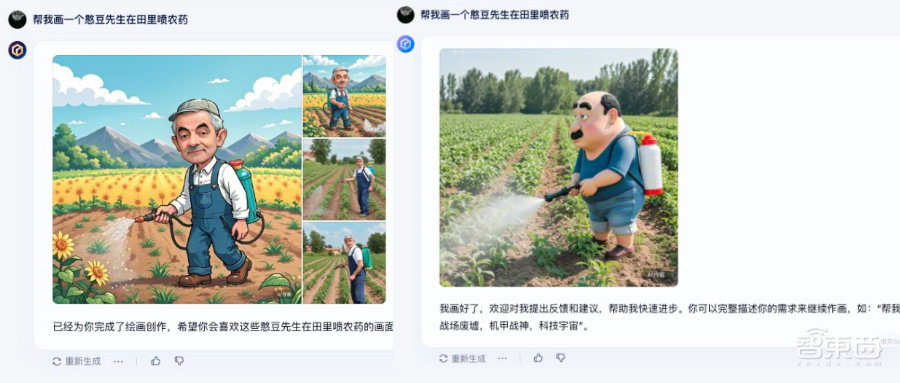
▲左图由文心大模型 4.0 生成,右图由文心大模型 3.5 生成(图源:百度)
而在 检索增强 方面,百度的生成式 AI 工具文心一言在 联网检索的准确性和内容描述的细致程度 上,明显优于 OpenAI 的 AI 聊天助手 ChatGPT。
先给它们一个有明确答案的问题:“2025 年,中国的法定假日有哪些?”

文心一言准确地指出了今年的中秋节与国庆节是连休的,但 ChatGPT 却错误地标记了中秋节的日期,并未识别出连休的特殊情况。

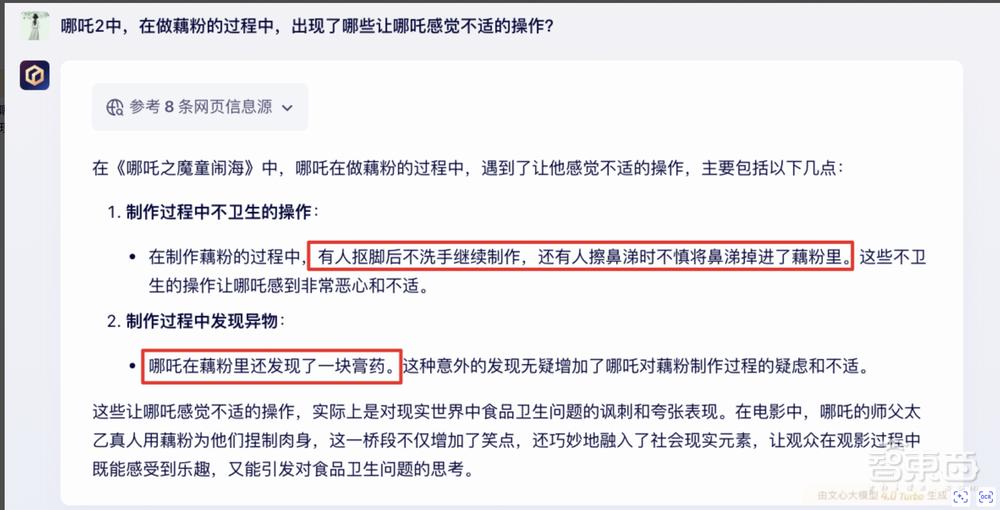
随后再给它们一个开放性的问题:“在哪吒 2 中,制作藕粉的过程中,出现了哪些让哪吒感到不适的操作?”
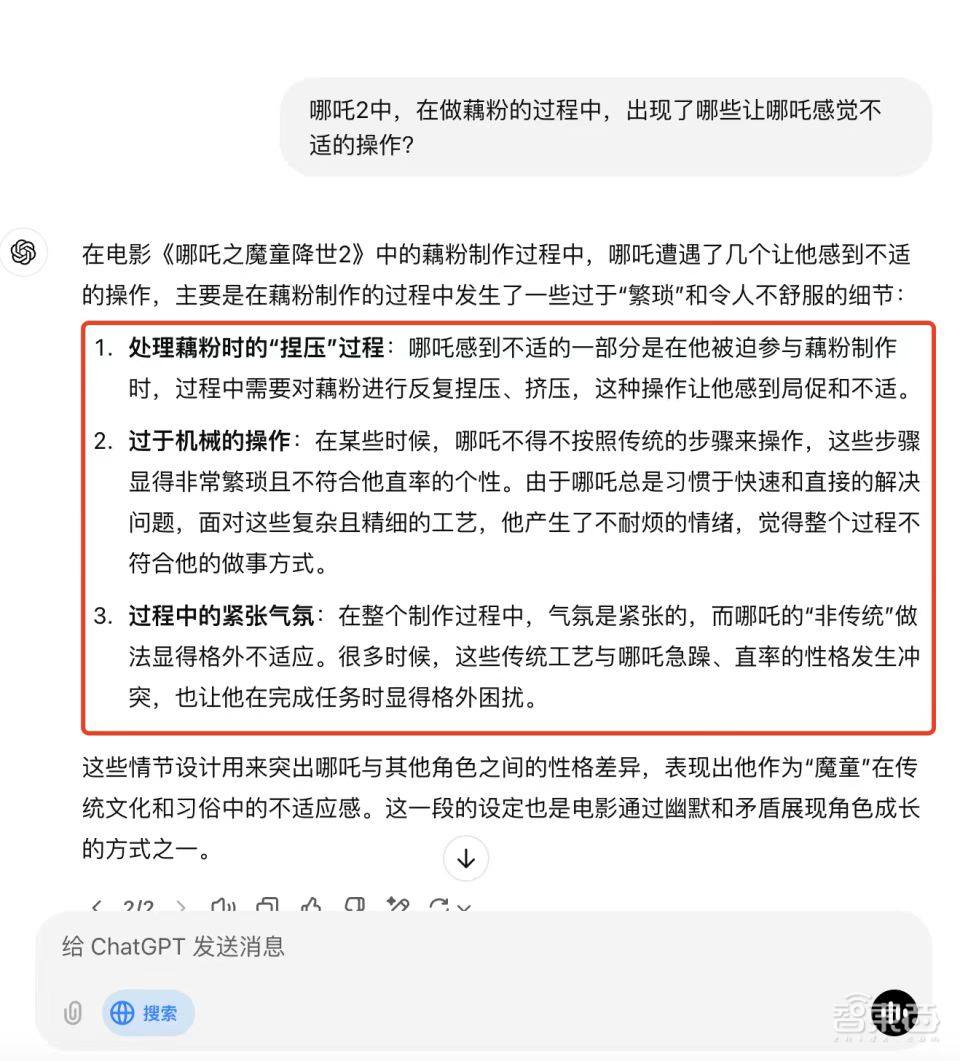
经过联网检索,ChatGPT 的生成答案在某些影片事实描述上出现了偏差,而文心一言则在细节方面表现得更加准确。
在今年,文心一言预计将能够处理一些 更具专业性和行业壁垒的 内容。此外,百度已于 2 月 13 日正式宣布,文心一言网页版上线深度搜索功能,App 端也将同步进行升级。
借助该深度搜索功能,文心一言能够应对 民生、创业以及经济分析等 专业咨询类问题,力求在内容回复上达到 专家级别的水平,从而有效突破之前在查询渠道狭窄以及专业领域解析困难等 AI 搜索的瓶颈。
除了提升搜索能力,百度方面还透露文心一言的 思维、规划和反思能力 也得到了进一步的增强,使其能够更加“聪明”地利用各种工具来解决复杂的任务。
例如,在面对一些无法简单处理的问题时,文心一言能够先“阅读”和“理解”用户上传的文档,接着进行相关信息的搜索与分析,最后综合利用私域和公域资源的信息,给出最终结果。
二、“芯”动力的支撑,显著提升模型训练效率
当前,在增强大模型及其产品性能的同时,控制和降低开发与使用成本也是关键,以实现对用户的开源和免费使用。这一切都离不开整体算力架构的优化提升。
首先,算力的“油门”体现在芯片上。
百度自主研发的AI 芯片“昆仑芯”,专注于优化大模型的训练和推理,为一系列文心大模型缩短训练周期并降低开发成本提供了动力。
目前,昆仑芯已升级至 第三代昆仑芯 P800。此芯片采用 XPU 架构(eXtensible Processing Unit,可扩展处理单元),这种处理器架构相较于传统的 CPU(中央处理单元)和 GPU(图形处理单元)具备更高的灵活性,能够根据特定需求和应用场景进行扩展和定制,从而减少算力浪费并提升计算任务处理效率。
同时,昆仑芯 P800 的显存规格相比同类主流 GPU高出 20% 到 50%,这使其能够更好地适应 MoE(Mixture of Experts,混合专家模型)架构,从而节省算力消耗,整体降低开发成本。
该芯片还 支持 8 -bit 量化技术 ,占用更少的显存,同时保持较高的推理精度。这意味着千帆 DeepSeek 一体机 在单机 8 卡的情况下,也能 驱动满血版 DeepSeek 等 参数量达到 671B 的大模型。
其次,算力的“油箱”就是数据中心。
本月,百度智能云宣布已完成昆仑芯第三代万卡集群的搭建,并计划将 万卡规模扩展至三万卡。
这套自研的万卡集群能够形成 规模效应 ,通过多任务并行处理和弹性算力管理等方式, 降低算力闲置现象,从而提高计算资源的利用率,有助于整体降低模型训练的算力成本。
未来,如果其规模按照计划从万卡扩大至三万卡,规模效应将进一步增强,百度的云计算服务整体成本可能会进一步下降。
最后,算力的“车底座”即为 AI 计算平台。
三、跨平台创新,显著降低模型推理成本
模型的训练与推理是其开发和应用中至关重要的环节,因此,仅仅降低训练成本是不够的,推理成本同样需要通过技术优化来加以控制。
截至目前,在开源平台 Hugging Face 上,获得最高点赞数的是国产模型 DeepSeek-R1。该模型基于 DeepSeek V3 进行训练,旨在提升推理性能。
随着多个主流大模型厂商的接入,以及对 DeepSeek-R1 和 DeepSeek V3 的蒸馏和计划开源自家先进模型,这一领域的格局可能会迎来变革。
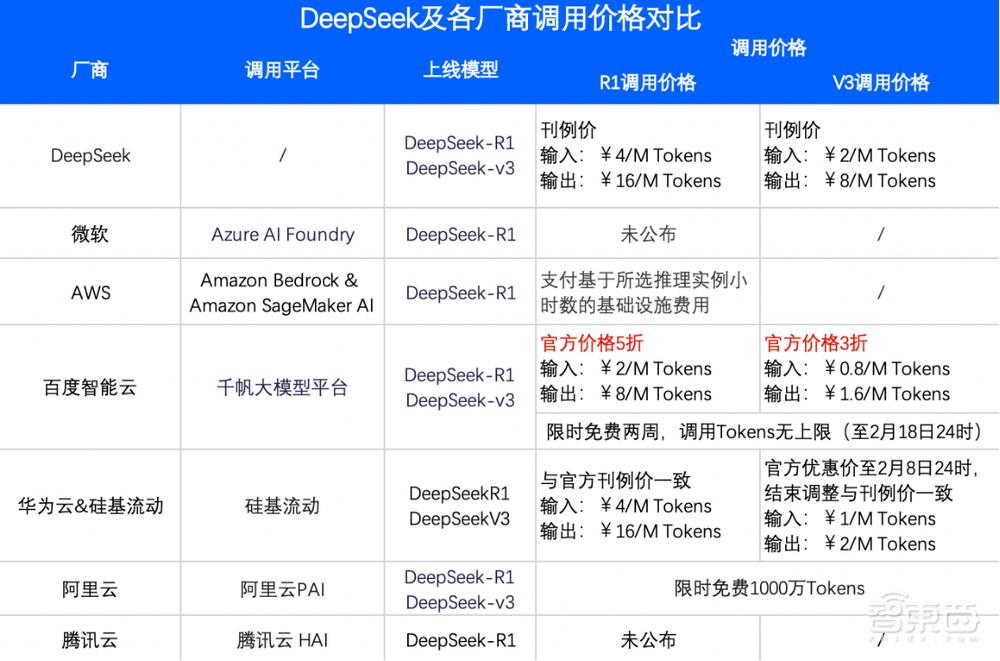
不过,调用 DeepSeek-R1 和 DeepSeek V3 的价格差异较大。
目前,诸如 DeepSeek 自家平台等,调用 DeepSeek-R1 和 DeepSeek V3 每百万 Tokens 的价格定价,最具性价比的是百度智能云千帆大模型平台。其中 R1 的调用费用仅为 DeepSeek 官方建议价的一半,而 V3 的费用则为其三分之一。
总体来看,百度通过优化 三个关键领域的推理技术,以实现推理成本的降低。
首先,百度智能云千帆大模型平台对 DeepSeek 模型的 MLA 结构(多级注意力)进行了深入优化,一方面,同步调用计算、通信和内存资源 以实现推理,另一方面,引入 Prefill/Decode 分离推理架构,使得在推理前对数据进行预处理,从而在满足低延迟标准的同时,显著提高吞吐量并降低推理成本。
其次,百度智能云千帆大模型平台还通过 增强系统的容错能力、减少多轮对话场景下的重复计算、加强安全防护措施 来进一步降低整体推理成本。
最后,有业内专家指出,百度的飞桨深度学习框架,以及其自研的并行推理和量化推理技术,能够迁移应用于文心一言等百度的 AI 产品,进而降低这些产品的推理成本。