共计 3745 个字符,预计需要花费 10 分钟才能阅读完成。

图片系 AI 生成
在 3 月 16 日,文心大模型迎来了其两周年庆典,百度随之发布了国内首款原生多模态大模型文心 4.5,以及深度思考模型 X1。这次发布与以往有所不同,百度没有举行传统的发布会,而是直接在文心一言官网上宣布了模型的上线,并且对用户免费开放。文心大模型 4.5 也向企业用户和开发者开放,用户可通过百度智能云的千帆大模型平台调用 API。同时,文心大模型 4.5 和 X1 也将逐步在百度搜索、文小言 APP 等产品中上线。
关于价格,文心大模型 4.5 的 API 调用费用为每千 tokens 输入 0.004 元,输出 0.016 元,约为 GPT4.5 价格的 1%;而文心大模型 X1 的定价则为输入 0.002 元 / 千 tokens,输出 0.008 元 / 千 tokens,预计将在千帆平台正式上线。
尽管文心大模型 4.5 被视为 4.0 版本的改进版,通常情况下,官方会通过发布会来介绍产品的技术亮点。与此形成对比的是,OpenAI 最近也举行了 GPT4.5 的线上发布会,而百度的选择则显得十分独特。
行业的氛围变得有些复杂,百度似乎比以往更需要重新证明其自身的地位。

百度再出发,争取重回行业巅峰
如果说 DeepSeek 的推出让全球大模型企业警醒,那么百度则通过一系列行动,展现了如何在这一领域继续保持竞争力。
以往的百度在某种程度上显得有些“偶像包袱”。自 OpenAI 推出 ChatGPT 以来,百度是国内较早推出同类大模型产品的公司,其“All in AI”战略也被认为前景可期。凭借其前瞻性的视野和技术储备,百度被誉为“中国版 OpenAI”。
科技行业的叙事从来不乏新意,正是由于其不可预测性,大模型行业的领先优势往往只能维持短暂的时间。随着各大巨头纷纷在生成式 AI 领域加大投入,业界逐渐形成了一个新的共识:“大模型已成为巨头们的游戏”。然而,DeepSeek 的开源和低成本策略又引发了新的热潮,让包括 OpenAI 和百度在内的所有 AI 企业意识到,大模型的未来并非一成不变。
正如百度创始人李彦宏曾言:“创新无法被计划,无法预测何时会出现,唯一能做的就是营造一个有利于创新的环境。”过去,百度的成功在于创造了一个适合创新的环境,而如今,百度必须摆脱“偶像包袱”,用实际行动来证明自己仍然值得一席之地。
积极的一面是,李彦宏不惜推翻之前的判断,迅速而果断地采取了一系列措施,比如文心一言完全免费、文心 4.5 将在 6 月 30 日正式开源,以及百度核心业务搜索接入 DeepSeek 等。
据悉,在文心 4.5 和 X1 大模型发布之后,百度还将推出文心 4.5 系列模型,以及下半年更新更先进的 5.0 版本。
与两年前的自己相比,百度已经明显提速。内部人士表示,无论是全面免费的文心 4.5,还是 PC 和移动端的现货推出,百度管理层几乎在短短半天内便做出了决策。
然而,这并不意味着百度完全失去了自己的节奏。文心 4.5 的原生多模态特性和 X1 的多功能调用,研发过程依然需要数月甚至一年,表明百度只是加快了自己的步伐,而非失去了对技术的敏锐度。
从长远来看,虽然百度在某些预判上可能存在失误,比如跟随 OpenAI 过早商业化的决策,但这并不妨碍大模型产业的基本逻辑。更前沿的大模型依然在路上,生态系统的重要性也在不断上升。
在人工智能时代,技术栈的不同层面需要协同优化,如芯片层、框架层、模型层和应用层,以大幅提升效率。百度自昆仑芯至飞桨深度学习框架,再到文心预训练大模型,均有布局,从而实现成本降低和创新效率提升。
回到此次发布,为什么百度选择了“默默无闻”的方式,而是以产品全量上线的形式?上述百度内部人士解释道:“发言不如发产品,现在百度说什么外界可能都会觉得不妥,最直接的方式就是用产品来证明,4.5 是一个升级版本,但其重要性与 5.0 相比差距明显,大家的危机感在上升,战略调整和技术迭代的效果需要时间去显现。”
作为百度重新证明自身的阶段性产品,文心 4.5 和深度思考模型 X1 透露出百度未来的哪些方向?
文心 4.5 的智慧提升,原生多模态的关键地位
文心 4.5 的策略在于通过多个模态的联合建模来实现协同优化,具备更为出色的语言能力,理解、生成、逻辑推理和记忆能力全面提升,并且在减少幻觉、逻辑推理及编码能力方面有显著进步。
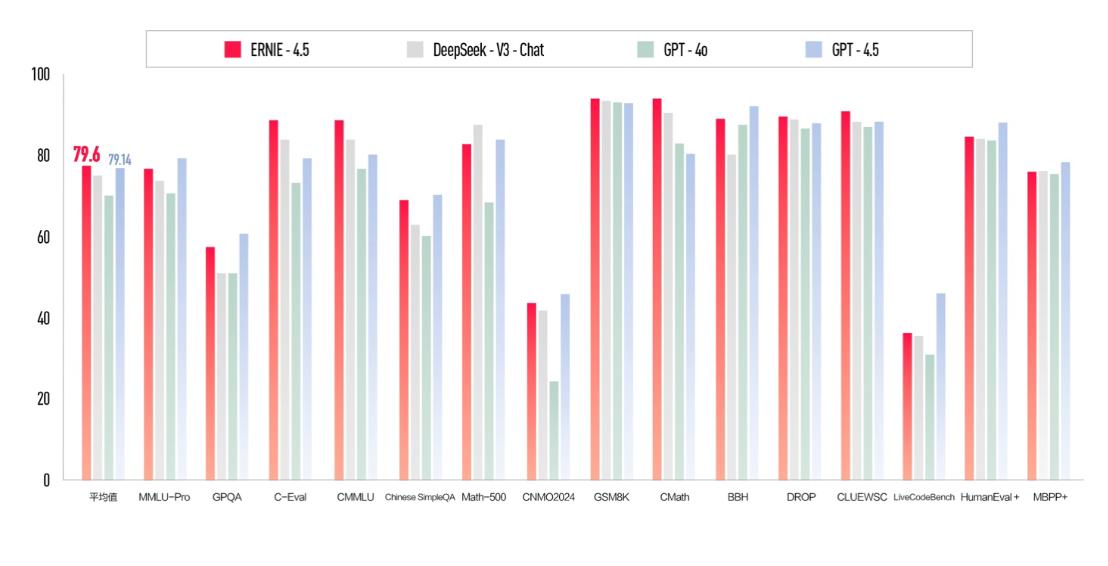
在多项基准测试中,文心大模型 4.5 的表现优于 GPT4.5 和 DeepSeek-V3,平均分达到 79.6,超过 GPT4.5 的 79.14。
特别需要强调的是“原生多模态”。李彦宏早前在人民网上发文对此进行了预告,原生多模态大模型打破了以往先训练单模态模型再进行拼接的方式,通过统一架构实现文本、图像、音频和视频等多模态数据的原生融合,从而对复杂世界进行统一理解,这标志着向通用人工智能(AGI)迈出了重要一步。
简而言之,原生多模态大语言模型自训练阶段起便利用不同模态的数据进行预训练,不仅在输入和输出端实现多模态,还具备强大的多模态推理能力及跨模态迁移能力。
微软早些时候提到,基于多模态数据原生训练的单一模态能力,应该超越仅在单模态数据上训练模型的性能。更为重要的是,在不同模态数据的学习过程中,模型应该能够涌现出新的能力。
从行业角度来看,GPT- 4 并不算是原生多模态大模型,其多模态功能是通过模型转换实现的,例如通过语音识别模型将语音转换为文字,或通过图像识别模型提取图像内容,再利用 GPT- 4 的大型语言模型生成回答。而在此之后,系统会决定向用户返回文本、图片或语音等不同输出方式,直到 GPT-4o,OpenAI 才展示出原生多模态的能力。
谷歌在模型能力方面滞后于 GPT,但在原生多模态上更早下注,将文本、语音、图像和视频的数据统一输入到一个预训练模型中,然后利用额外的多模态数据进行微调,以进一步提升其有效性。
百度文心 4.5 也实现了多项创新,例如多模态异构专家扩展技术,能够根据模态特点构建模态异构专家,并结合自适应模态感知损失函数,解决不同模态梯度不均衡的问题,提升多模态融合能力。
此外,还引入了 FlashMask 动态注意力掩码技术,有效提升长序列建模能力与训练效率,优化长文处理及多轮交互表现;时空维度表征压缩技术显著提高多模态数据训练效率,增强从长视频中获取世界知识的能力;基于知识点的大规模数据构建技术能够构建高知识密度的预训练数据,提升模型学习效率,并显著降低模型幻觉;以及基于自反馈的后期训练技术,增强强化学习的稳定性与鲁棒性,从而提升预训练模型对齐人类意图的能力。
文心 4.5 的能力在图像视频理解、图片生成、RAG 测试、逻辑测试以及文本创作等方面表现突出。文心 4.5 支持上传文档、图片、音频及视频文件,兼容多种常见格式,目前在文件大小上有所限制,比如单个视频文件大小不超过 20M,这可能与效率和成本有关。
钛媒体 App 实测了多个应用场景,如上传视频并请求文心 4.5 介绍内容,以及要求其提供视频文本版本,均能准确回答。此外,上传电影《肖申克的救赎》片段,文心 4.5 也能够识别并给出可能的情节发展。如果文心 4.5 能够推荐合适的背景音乐,它也能依据视频的情感基调提供建议,展现了其跨模态输出能力。

深度思考模型 X1,AI 智能体的初步形态
文心 X1 是基于百度在 2023 年 10 月推出的慢思考技术而发展起来的,具备更强的理解、规划、反思和进化能力,同样支持多模态功能。
以电车难题为例,深度思考的文心 X1 提供了详细的解答,最终选择了拉动操纵杆,将列车切换至另一条轨道,其结论是:在封闭的条件下,基于功利主义选择最大化生存数量的原则,牺牲 1 人以拯救 5 人。但应警惕此类逻辑的滥用,并时刻反思其伦理界限。

文心 X1 展现出更全面的深度思考能力,其观点输出更为直白,减少了“端水”现象。面对复杂问题,文心 X1 能够结合网络搜索的最新信息,详细拆解并给出全面的回复。例如在规划旅游项目时,其可行性更高且更符合实际需求。
钛媒体 APP 了解到,文心 X1 采用了递进式强化学习训练方法,并基于思维链和行动链进行端到端训练,同时建立了统一的评估系统,融合多种类型的奖励机制,在中文知识问答、文学创作、文稿写作、日常对话、逻辑推理、复杂计算及工具调用等方面表现优秀。
其中,多工具调用能力值得关注,这是文心 X1 的显著特点之一。目前,X1 支持高级搜索、文档问答、图片理解、AI 绘图、代码解释、网页链接读取、TreeMind 树图、百度学术检索、商业信息查询、加盟信息查询及词云生成等多种工具,这对大模型的应用落地具有积极意义。
X1 也证明了一个事实:大模型能力的进步将淘汰部分智能体。如果某些智能体能够被大模型原生替代,便说明这些智能体的价值有限,在这一领域的创业注定面临挑战。
近期爆红并引发争议的 Manus 等产品,在未来一段时间内也将面临类似的困境。Manus 的成功并非源于大模型的原创性突破,而是对现有技术的工程化整合,如 Claude 模型、Computer Use、MCP 协议等,其核心创新在于将虚拟机环境与多智能体协作架构结合,使得 Agent 能够像人类一样完成复杂任务。
这同样透露出百度在另一个方向上的坚定信念,即 AI 智能体的落地。李彦宏提到,推理型大模型展现出惊人的深度思考能力,这将推动人工智能的一个重要应用方向,即“AI 智能体”的实现。预计到 2025 年,这一领域可能会迎来爆发的元年。(本文首发于钛媒体 APP,作者 | 张帅,编辑 | 盖虹达)