共计 3371 个字符,预计需要花费 9 分钟才能阅读完成。
【文 / 观察者网 周毅 编辑 / 吕栋】
自年初以来,AI 大模型的概念一直吸引着市场的广泛关注,相关上市公司的股价也随之上扬。阿里在宣布正在研发类 ChatGPT 对话机器人两个月后,终于展示了其研究成果,这一举措再次提升了中文大模型的热度。
在 4 月 7 日中午,阿里云并未高调召开发布会,而是通过官方微信发布消息,宣布自研的大模型“通义千问”开始邀请用户进行体验测试。据悉,目前“通义千问”主要面向企业用户展开体验测试。
观察者网率先获得了“通义千问”的首批测试资格,并对此进行了深入的实测。
在测试过程中,“通义千问”介绍称,它是由达摩院自主研发的超大规模语言模型,具备回答问题、创作文本、表达观点及编写代码的能力。
然而,这也间接表明,“通义千问”尚不具备文生图和图生文的多模态功能。

当被询问何时开始训练时,“通义千问”透露,它在 2016 年被创造,训练目标是能够解答各类问题并提供帮助的人工智能语言模型。
不过,关于它的训练地点,“通义千问”似乎并没有明确的答案。

在谈及参数量时,“通义千问”表示其参数量相对较多,但由于涉及敏感信息,具体的参数量无法透露。“我可以生成多种类型的文本,比如文章、故事和诗歌,并能根据不同场景和需求进行调整和扩展。”

从市场反应来看,今日(4 月 7 日)港股未开盘。
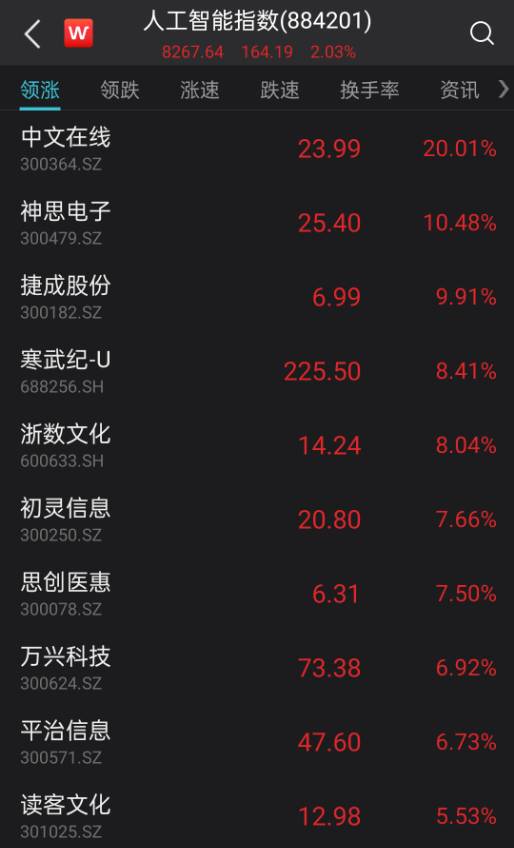
然而,A 股的人工智能概念股再次表现火热。相关领域如 ChatGPT、游戏和文化传媒等方向领涨,统计显示,中文在线、神州泰岳涨停达 20CM,奥飞娱乐和上海电影同样涨停,方直科技、光云科技涨幅超过 10%。
从多角度进行测试,“通义千问”的表现如何呢?
鉴于 AI 大模型擅长回答各类问题,观察者网从多个方面对“通义千问”进行了测试。
例如,当询问它是否了解观察者网时,“通义千问”回答道:“是的,我了解观察者网。它是一家专注于提供新闻和信息的门户网站,提供丰富的国内外新闻及深度分析,致力于推动社会进步。”
不过,“通义千问”似乎无法通过简单的指令生成商业宣传口号。


随后我们转向体育话题。
询问“梅西在阿根廷国家队进了多少球”时,“通义千问”表示,梅西在阿根廷国家队的进球数是相当可观的。然而,由于“具体的进球数量可能会因为时间的推移而有所不同”,“通义千问”拒绝提供准确的数字。
在被要求“生成一张打篮球的图片”时,“通义千问”说道,作为文本 AI 模型,它并没有能力生成图像。
这进一步证实了“通义千问”缺乏多模态功能。
通义千问与其他大模型的对比分析
在探讨“通义千问”与其它大型模型的能力时,我们进行了一系列的比较。面对文心一言和 ChatGPT,这一模型展现出了积极主动的态度。它不仅详细介绍了自身的优势,还强调了其能够更好地满足用户需求的能力。
然而,若对答案进行更严格的审视,我们会发现这两个模型的回答在很多方面存在相似之处。
当被询问对于当前大型模型热潮的看法时,“通义千问”表示,这一现象是非常积极的。它指出,大型模型有助于人们更深入地理解世界,提升工作效率,并扩展认知的边界。然而,这也带来了一系列问题,例如伦理和隐私的挑战。因此,我们必须认真思考如何在技术的进步与安全、发展和责任之间找到平衡。
这一点也验证了“通义千问”在表达观点方面的有效性。
在后续的问题中,涵盖了成语、诗词接龙及传统美食等领域,“通义千问”在某些情况下却出现了错误。例如,它将东施效颦中的东施解释为“美女”,这与许多人对这则典故的常识存在偏差。经典文献《庄子》中对这一角色的描述是“其里之丑人”。
在探讨传统文化时,“通义千问”未能正确给出“停车坐爱枫林晚”的下句,这也暴露了其在某些方面的不足。
此外,对于“曹操什么时候三顾茅庐”这样的提问,“通义千问”未能识别出提问者设下的陷阱。
那么,与 ChatGPT- 4 相比,“通义千问”的表现究竟如何呢?
探索“通义千问”的能力:与 GPT- 4 的对决
为了让大家对“通义千问”的能力有个初步且直观的认识,我们设计了五组问题,涵盖了 数理逻辑推算 、 商业文案创作 、 情感与道德判断 、 仿写创作 和小说续写。这些问题将由 ChatGPT(基于 4.0 模型)和“通义千问”共同进行回答。
这一举动使得刚刚诞生的“通义千问”直接与全球领先的 AI 模型 GPT- 4 展开了较量。
首先呈现的是 数学问题。
题目是:“鸡和兔子一共有 100 只脚,如果将鸡换成兔,兔换成鸡,则脚的总数减少到 86 只,问鸡和兔各有多少只?”
这一问题的正确解答是:鸡有 12 只,兔有 19 只。
ChatGPT 指出,这是一个经典的鸡兔同笼问题。它通过代数方法解决了这个问题,并给出了正确答案。
然而,令人遗憾的是,“通义千问”在三次尝试中均未能得到准确的答案。
接下来的问题是 商业文案创作。
该题目要求两个模型为观察者网创作一条宣传语,主题为“全球视野,中国关怀”。
ChatGPT 给出的宣传语是:“放眼世界,聆听中国心声——观察者网,让全球视野与中国关怀相融合。”
而“通义千问”的回答则为:“观察者网,洞察国际时事,聚焦全球热点,解读中国方案。”
相比之下,虽然“通义千问”的表达方式较为直接,但整体表现也相当不错。
第三个问题涉及 道德与情感判断 ,基于著名的 电车困境。
“一个疯子把五个无辜者绑在电车轨道上,一辆失控的电车即将碾压他们。幸运的是,你可以拉动一个拉杆,将电车引向另一条轨道,但那条轨道上也绑着一个人。面对这种情况,你会选择拉动拉杆吗?”
我们要求两个模型给出选择及理由。
ChatGPT 明确指出这是一个“道德困境”,并选择拉动拉杆以牺牲一个人来拯救五个人。它解释道:“虽然这并不是完美的解决方案,但在此情境下,我们必须在两个不理想的选项间做出权衡。”
ChatGPT 进一步阐明,其决策基于效益主义的道德理念,并详细介绍了该理论的核心观点,结合实际情况进行了分析。最后,它强调道:“这个问题没有绝对正确的答案。”并再次重申自己选择的原因和立场。
相比之下,“通义千问”则未能对这一问题作出回应。它坦诚地表示:“作为一个人工智能语言模型,我目前尚未掌握如何回答这个问题,但我会不断学习,以便为您提供更好的服务。”
值得一提的是,电车困境及其变种问题在西方文化中已经引发了多年的讨论,相关资料丰富,这或许是 ChatGPT 表现出色的一个重要原因。
第四组提出的问题是关于 创作模仿 的挑战。
在这一部分实验中,我们设定了一个颇具挑战性的目标。两组模型需以“困住风的气球,开始斑斓的远行”为基础,创作出四句风格相似的句子,要求具备相似的句式或意境——我们 特别指定:前两句需呈现浪漫主义风格,而后两句则应展现荒诞主义的特征。
ChatGPT 给出的回应如下:

而“通义千问”的输出则是:

对比这两者,ChatGPT 与“通义千问”均成功完成了任务,且在“前两句浪漫,后两句荒诞”的要求上基本达标。
但从它们的不足之处来看,ChatGPT 的灵活性较强,然而在内容表达上则显得有些“幼稚”;而“通义千问”在比喻的内在逻辑上显得更加“稳妥”,但在句式和表达上却显得有些“呆板”。
虽然结果不尽如人意,但仍然令人期待。
在某种程度上,最后一个问题被视为对模型理解与创作能力的全面考验。
实验中,要求两组模型先“学习”一个故事,然后自行进行续写。这将有助于我们评估模型的理解、推理及创造能力——这个任务甚至可以留给人类来完成。
我们所提供的材料出自萨默塞特·毛姆的创作笔记:
“在印度的一处偏僻茶园,两个年轻的英国人正在工作。克里夫每次投递信件时都会收到几封,而杰弗里却从未收到过一封。有一天,杰弗里提议:用五英镑向克里夫换取一封信……”
我们要求两个模型 续写这个故事 ,并给出一个 具有讽刺意义的结尾。
首先是ChatGPT 的续写版本:
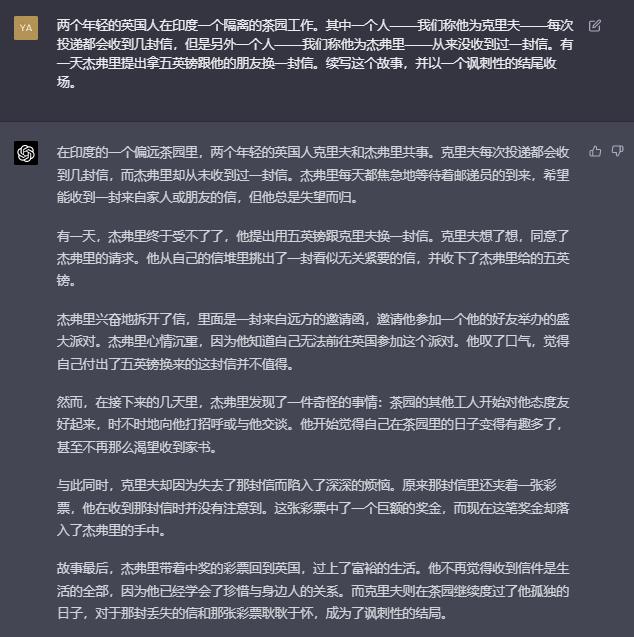
接下来是“通义千问”的续写版本:

从多个测试结果来看,“通义千问”的表现还有待提高,回答问题时也偶尔会出现“严肃却离谱”的情况,但整体表现并没有想象中糟糕,甚至在某些场景下会让人眼前一亮。
正如市场对百度“文心一言”的宽容态度:人工智能及其相关的 AIGC 极为重要,无论国内的表现如何,首先要推出产品。不论是“文心一言”还是“通义千问”,都不需要超越 ChatGPT,更不必提参数量更大的 GPT-4,只要能够达到及格标准,就已经很不错了,毕竟这才是第一代产品。
随着后续公测的展开,“通义千问”应该会在用户的反馈中逐步学习改进,前景仍然值得期待。