共计 732 个字符,预计需要花费 2 分钟才能阅读完成。
深入探讨 RL 训练中的样本筛选与遗忘现象
在强化学习(RL)训练中,将模型生成的 N 次完全正确的样本视为“简单样本”并加以筛除,以提升后续训练效率,已逐渐成为一种普遍做法。
然而,我对此产生了一些担忧。在某些实际问题中,样本的复杂性并不能简单地用“简单”或“困难”来界定。不同样本可能来源于不同的领域,模型在 RL 前可能擅长处理领域 A,而在 RL 后则转向领域 B。由于长时间未接触领域 A 的样本,模型可能会出现遗忘现象,导致它在“简单”问题上反而表现不佳。
当然,这只是我的一种假设。我想请教各位专家,是否在实际操作中遭遇过类似的情况?或者是否可以完全无视地筛掉“简单”样本呢?
在 RL 训练过程中,模型确实可能会遗忘原有的简单问题。此外,在目前的 GRPO 设置中,N 次完全正确的样本组内其优势值(advantage)也是零。如果不将这些样本筛除,它们对训练并没有任何帮助。
至于您提到的领域 A 和领域 B 之间的遗忘现象,情况确实非常严重。例如,在我下面的实验中,经过 SQL 训练的模型在数学领域的 OOD 测试中表现不佳,无论是无 KL 的 GRPO、DAPO,还是 Reverse KL+DAPO,结果都显著下降:
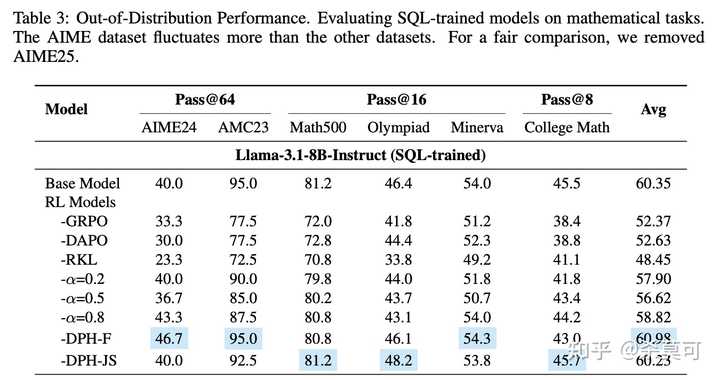
DPH 是我在论文中提出的方法,也是我们公司用于保持模型稳定性的策略。我们将数据集分为两类,N 次完全正确的样本通过另一种 f -divergence 加以控制,而其余数据则进行无 KL 的探索。
有关详细信息,欢迎参考我的论文:THE CHOICE OF DIVERGENCE: A NEGLECTED KEY TO MITIGATING DIVERSITY COLLAPSE IN REINFORCEMENT LEARNING WITH VERIFIABLE REWARD
https://arxiv.org/pdf/2509.07430