共计 1832 个字符,预计需要花费 5 分钟才能阅读完成。
作者 | 咸菜
编辑 | 江娱迟
在 2025 年世界机器人大会结束后,北京国贸大厦的灯光依然明亮,产品经理小张目不转睛地凝视着电脑屏幕上空白的“具身 AI 赛道可行性分析”文档,烟灰缸里已经堆积了五个烟蒂。
撰写这样一份需要技术背景、市场洞察以及政策引导的调研报告,过去往往需要熬夜三天才能完成,如今业内都在传“AI 可以作为半个助理”,可真正动手操作时,才意识到这并非易事。
我们对当前市场上最受欢迎的七个 AI 大模型进行了“高考”,主题为“具身 AI 赛道是否值得投资”,并从专业性、逻辑性、数据准确性及操作便捷性四个方面进行评分。

考核规则
此次评估如同为 AI 们设定了一份实战试卷,考题为撰写一份具身 AI 领域的可行性调研报告。
其目的在于为公司的战略部门提供决策参考,必须分析技术前景,还要掌握市场现状,类似于为准备开店的创业者进行全面的商圈调研。
我们设计了两种“出题方式”:一是宽泛的提示词,只要求“写一份具身 AI 调研报告”,以便观察 AI 能否自主抓住重点。

第二种则是详细的提示词,列出了报告的框架和必需包含的模块,以模拟专业用户的实际需求。
评分标准共分为四个方面:报告的专业性占 40 分,检验是否能够深入阐述技术路线和竞争对手分析等核心内容;逻辑与结构占 30 分,考察报告的框架是否明确;数据准确性为 20 分,重点关注是否存在虚构数据或伪造来源;操作便捷性占 10 分,查看是否需要复杂的指令才能输出,是否支持导出为 Word 或 PPT 等实用格式。

成绩分析
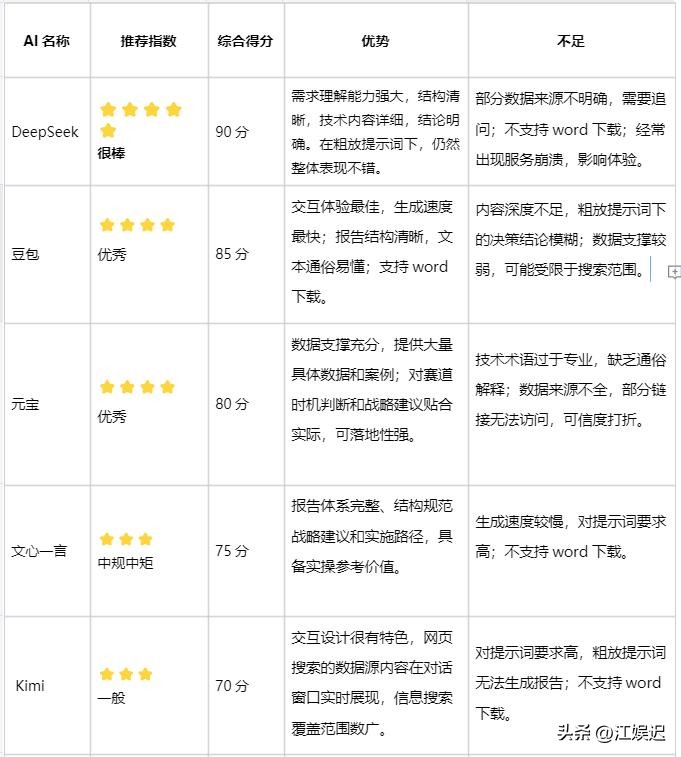
在这场测试中,DeepSeek-R1 以 90 分的优异成绩当选状元,这个模型可谓是典型的“技术天才”,无论是面对宽泛还是详细的提示词,都能将具身 AI 的核心技术、市场趋势及政策解读写得相当出色,甚至在战略建议中蕴含了商业决策的价值。
更为难得的是,这个模型的数据来源标注得清晰明确,诸如凤凰网、CSDN 等可信媒体的链接直接嵌入文中,写作规范如同学术论文。
但这位学霸也有短板,常常在答卷过程中出现卡顿,服务偶尔崩溃,急需时让人感到焦虑,而且它只支持纯文本输出,想要导出为 Word 还得手动复制,显得不够人性化。
字节跳动的豆包以 85 分排名第二,成为最具中文理解能力的“贴心课代表”,这个模型报告撰写速度极快,文档结构清晰明了,善于用表格突出重点,阅读起来毫不费力。
更为加分的是,它的操作简单,无需复杂指令便能生成高质量内容,还能直接导出为 Word 和 PPT,成为急需报告者的得力助手。
然而,它在数据准确性方面扣了不少分,宽泛提示词下的报告没有标注数据来源,而详细提示词下的来源标注中,很多链接要么失效要么过期,显得有些不靠谱,仿佛引用名人名言却记错出处。

腾讯元宝以 80 分名列第三,展现出“学术派”的优等生风范,它的数据支持最为扎实,市场分析中充满了具体数字,战略建议也直切要害,避免了空洞的陈述。
但这个模型的表达却显得过于学术化,术语使用频繁,缺乏通俗易懂的解释,就像在读教科书一样,同时与 DeepSeek 类似,仅支持查看而不支持导出为 Word,使用体验略显局限。
剩下的几位考生表现就不算太理想,百度文心一言以 70 分得分中规中矩,Kimi 则以 65 分勉强及格,内容深度明显不足。
最让人失望的则是 ChatGPT,曾经的明星这次仅获得 60 分,堪堪过关。

选择指南
挑选 AI 工具就如同选择厨师,名气大并不意味着适合你。如果你的技术团队强大,需求深入的分析报告,并且能够接受偶尔的卡顿,DeepSeek 是最佳选择,毕竟其专业性是显而易见的。
若你急于完成报告,重视操作便捷和中文表达,豆包更像随叫随到的得力助手,尽管在深度上有所欠缺,但效率极高;如果你的老板偏爱以数据为依据,元宝的严谨风格将为你的汇报增添分数。
但必须提醒大家的是,尽管这些 AI 表现出色,它们仍然只是工具。即便 DeepSeek 的数据来源再可信,你依然需要亲自查阅链接以核实信息,而豆包即便导出 Word 的功能再便利,关键的结论也要自己把控。
在这次评测中发现,任何 AI 都有可能犯错,有些将 2023 年的数据误称为 2025 年,还有些对政策的解读引用了过时的文件。

总结
最后,必须指出的是,以上评分仅为个人在考场上的直观感受,各厂商请勿过于计较,毕竟 AI 的进步如同翻书般迅速,也许下个月再测评时,排名就会发生变化。
对产品经理而言,与其纠结于哪个 AI 工具最好,不如先明确自己的需求,是否需要快速出稿的效率,还是希望在专业度上毫无瑕疵,合理利用工具,才能使 AI 真正成为得力助手,而非麻烦的“猪队友”。